Hi folks,
We would like to present a proposal to add matching and inference functionality to Propeller, a link - time optimization technique, and seek your valuable feedback.
[RFC] Adding Matching and Inference Functionality to Propeller
Authors: Dexin Wu(wudexin@kuaishou.com), Fengxiang Li(lifengxiang@kuaishou.com), Minghui Wu(wuminghui03@kuaishou.com)
Summary
Propeller is a link-time optimization technique that offers optimization effects comparable to BOLT, with lower memory usage and shorter execution time. The current version of propeller has zero tolerance for changes in build parameters and source code. This means that using a stale profile for propeller optimization can lead to negative optimization. Additionally, when using the same profile for both AutoFDO optimization and propeller optimization, it can also result in poor or even negative optimization effects. This issue has a negative impact on the practical use of propeller in production environments.
To address this problem, we referred to the matching and inference functionality in BOLT and plan to introduce it into propeller. In the experiment, we used the same profile file to conduct autofdo and propeller optimizations simultaneously. The results show that after introducing the matching and inference function, the propeller optimization no longer has a negative impact on the autofdo optimization. Instead, it can bring an additional benefit of 2-3%.
Problem statement
In propeller, “hot” Machine Basic Blocks (MBBs) are extracted from functions based on the sampled execution frequencies to form clusters. In the generated cluster configuration file, MBBs are identified by Basic Block IDs (BBIDs). However, BBIDs are extremely unstable. Minor code changes or variations in build parameters can cause significant changes to BBIDs. In this case, if we still use the original BBIDs to identify clusters, it will lead to incorrect identification of “hot” MBBs, resulting in negative optimization. This is the reason why propeller has zero tolerance for changes in build parameters and source code.
Approach
Inspired by the way BOLT handles stale profile files, we use the hash value of MBBs to identify them in the profile file. The calculation method of the MBB hash value is the same as that in BOLT. The hash includes {Offset, OpcodeHash, InstrHash, NeighborHash}. Specifically, the profile contains the hash values of MBBs and the sampled frequency information. When using the profile file, we match the hashes in the profile with the hashes of MBBs. If the match is successful, we mark the frequency of the MBB as the frequency in the profile. After the matching is completed, we use an inference algorithm to estimate the frequencies of other MBBs. Finally, we select the “hot” MBBs based on the complete MBB frequencies.
Since the hash value of MBBs is more stable than BBIDs and is less affected by changes in build parameters and source code, and the inference algorithm further enhances this stability. Therefore, introducing matching and inference can significantly improve propeller’s tolerance for changes in build parameters and source code, making it easier to use in practical production environments. The specific changes include the following points:
- Add MBB hashes to the BBAddrMap section: The hash includes four parts: {Offset, OpcodeHash, InstrHash, NeighborHash}.
- Offset: The offset of the MBB within the function.
- OpcodeHash: The hash of the instruction opcodes in the MBB (including only opcodes, not operands).
- InstrHash: The hash of the instructions in the MBB (including both opcodes and operands).
- NeighborHash: The OpcodeHash of the direct predecessors and successors of the MBB in the Control Flow Graph (CFG).
In the LLVM CodeGen part, add a MachineBlockHashInfo Pass to calculate the hash value of each MBB in every MachineFunction. In the AsmPrinter, write the hash value of the MBB to the BBAddrMap.
- Add a new propeller profile file format: The format is as follows:
!foo
!!0x1dce0b85df8f0000 2 0
!!0x28d413540c67002d 1 1
!!0xd7da78be7050003e 1 3
!!0x4e970dad93b80057 0 2
Lines starting with “!” represent the function name. In lines starting with “!!”, the first element is the hash value of the MBB, the second element is the sampled frequency of the MBB, and the third element is the BBID.
In CodeGen, add a FuncHotBBHashesProfileReader Pass to read the new propeller profile format and store the mapping information between the parsed MBB hashes and frequencies.
- Add a new HotMachineBasicBlockInfoGenerator Pass: Before generating the cluster of the MachineFunction, add this pass. It first retrieves the mapping information between hash values and frequencies from the FuncHotBBHashesProfileReader and matches the hash values with the MBBs in the current MachineFunction. If the match is successful, it records the frequency of the matched MBB as the corresponding frequency in the profile. The matching method is the same as that in BOLT, and the matching principles are as follows:
- (a) The OpcodeHash must be the same for a match.
- (b) From the MBBs with the same OpcodeHash, select the MBBs with the closest distance based on InstrHash and NeighborHash.
- (c) If multiple MBBs are selected in (b), choose the one with the smallest offset.
After the matching is completed, call the inference algorithm to estimate the frequency information of all MBBs in the MachineFunction. Select the entry MBB and MBBs with a frequency greater than zero as “hot” MBBs.
- Create clusters for “hot” MBBs in BasicBlockSections: If the new format of the propeller profile is used, create a cluster for the “hot” MBBs identified in step 3.
How to use matching and inference in propeller?
- Build the base binary: Use the -fbasic-block-address-map options to build the base version of the binary file. The generated BBAddrMap section will include the hashes of basic blocks.
$ clang++ -O2 -gline-tables-only -fdebug-info-for-profiling -funique-internal-linkage-names -fbasic-block-address-map code.cc -o base_code
- Generate the profile: Run the base binary and use the perf tool to collect samples and obtain perf.data. Use create_llvm_prof to convert it into a profile. Use the --use_bb_hash parameter during the conversion to generate a new propeller format file.
$ perf record -b ./base_code
$ create_llvm_prof --binary=./base_code --format=propeller --use_bb_hash --profile=perf.data --out=code.propeller
- Recompile for optimization: Recompile to generate the optimized binary file. During compilation, use the -fpropeller-profile-use compilation parameter to pass in the new propeller profile, and use -mllvm, -propeller-match-infer to enable the matching and inference functionality. The linking parameter needs to use -Wl, --propeller-profile-use to pass in the propeller profile.
$ clang++ -O2 -gline-tables-only -fdebug-info-for-profiling -funique-internal-linkage-names -fpropeller-profile-use=code.propeller -mllvm,-propeller-match-infer -Wl,--no-warn-symbol-ordering -Wl,--propeller-profile-use=code.propeller -fuse-ld=lld code.cc -o base_code
Experimental data
In the experiment, we used clang to compile itself to evaluate the effectiveness of the propeller optimization with the matching and inference function. We denoted the unoptimized clang as base_clang. Since there were significant differences in the MachineFunction between base_clang and the clang optimized by AutoFDO, directly using the profile sampled from base_clang for AutoFDO and propeller optimizations would result in a low matching rate during the matching process, thereby affecting the final outcome.
Therefore, in the actual experiment, we first sampled base_clang and applied AutoFDO optimization to obtain the optimized binary base_autofdo_clang. Next, we sampled base_autofdo_clang to get a profile. Using this profile, we performed AutoFDO optimization to obtain autofdo_clang, conducted both AutoFDO and the original propeller optimization to get autofdo_ori_propeller_clang, and carried out AutoFDO and the propeller optimization with matching and inference to obtain autofdo_my_propeller_clang.
We measured the compilation times of clang by base_clang, autofdo_clang, autofdo_ori_propeller_clang, and autofdo_my_propeller_clang. The results are shown in the following table:
| Version | Time | Optimization Ratio |
|---|---|---|
| base_clang | 355.3s | - |
| autofdo_clang | 308.4s | 13.2% |
| autofdo_ori_propeller_clang | 334.5s | 5.9% |
| autofdo_my_propeller_clang | 299.8s | 15.6% |
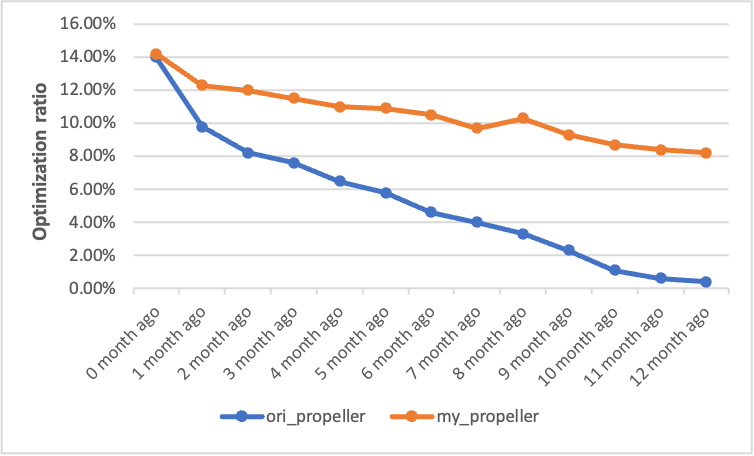
From the results, we can observe that when using the same profile for both AutoFDO and the original propeller optimizations, the propeller optimization had a negative impact on the AutoFDO optimization. The performance of the optimized clang significantly declined compared to that of the clang optimized only by AutoFDO. However, when using the same profile for AutoFDO and the propeller optimization with the matching and inference function, the propeller optimization did not degrade the effect of AutoFDO optimization. Instead, it brought an additional 2.4% performance improvement.
In addition, we also conducted verification on several C++ services in our company. When using a single profile for AutoFDO and the original propeller optimizations, the propeller optimization always degraded the effect of AutoFDO. In contrast, when using the same profile for AutoFDO and the propeller optimization with the matching and inference function, the propeller optimization on average brought an additional 2% performance improvement.