Stepping through optimized programs is often a trial, and one significant factor is jumping back and forth between source locations even in linear code. We (Sony) have prototyped a solution that reduces stepping jumpiness by making LLVM’s is_stmt placement smarter.
I’ll discuss this project in my upcoming LLVM talk “Improving optimized code line table quality”.
Quick summary
A lot of the noise in stepping comes from code motion and instruction scheduling. This is reasonable; a long expression on a single line may involve multiple operations that are moved, re-ordered, and interleaved with other instructions by optimisations. But we can eliminate a lot of that noise.
LLVM chooses whether to apply is_stmt (DWARF flag to indicate recommended breakpoint locations in the line table) using simple heuristics that are essentially just “has the line number changed since the last instruction?”.
Taking ideas from two papers [1][2] that explore the issue, especially @cmtice’s:
From the perspective of a source-level debugger user:
- Source code is made up of interesting constructs; the level of granularity for “interesting” while stepping is typically assignments, calls, control flow. We’ll call these interesting constructs Atoms.
- Atoms usually have one instruction that implements the functionality that a user can observe; once they step “off” that instruction, the atom is finalised. We’ll call that a Key Instruction.
- Communicating where the key instructions are to the debugger (using DWARF’s is_stmt) avoids jumpiness introduced by scheduling non-key instructions without losing source attribution (non-key instructions retain an associated source location, they’re just ignored for stepping).
Our prototype looks like this:
- 2 new fields added to DILocation metadata.
- The new fields are assigned values in a pre-optimisation pass that chooses “interesting” instructions (linear scan over instructions).
- There’s some middle end upkeep.
- There’s a map and remap function pair that need to be called for instructions cloned when control flow is duplicated, e.g. during loop unroll. CloneBasicBlock maps the metadata and RemapInstruction(s) remaps it, so a bunch of transformations don’t actually need to do anything new in practice.
- Other than that, the new metadata is propagated organically being a part of DILocation.
- During DWARF emission, the new metadata is collected (linear scan over instructions) to decide is_stmt placements.
Compile-time-tracker reports this instructions:u overhead on CTMark compile times:
stage1-ReleaseLTO-g
| Benchmark | Old | New |
|---|---|---|
| kimwitu++ | 59076M | 59540M (+0.79%) |
| sqlite3 | 61163M | 61616M (+0.74%) |
| consumer-typeset | 54620M | 55142M (+0.96%) |
| Bullet | 111784M | 112269M (+0.43%) |
| tramp3d-v4 | 176555M | 177689M (+0.64%) |
| mafft | 38854M | 39137M (+0.73%) |
| ClamAV | 85975M | 86536M (+0.65%) |
| lencod | 118636M | 119331M (+0.59%) |
| SPASS | 77932M | 78433M (+0.64%) |
| 7zip | 272642M | 273848M (+0.44%) |
| geomean | 89451M | 90042M (+0.66%) |
stage1-O0-g
| Benchmark | Old | New |
|---|---|---|
| kimwitu++ | 24932M | 25167M (+0.94%) |
| sqlite3 | 4823M | 4938M (+2.39%) |
| consumer-typeset | 12635M | 13114M (+3.79%) |
| Bullet | 65029M | 65445M (+0.64%) |
| tramp3d-v4 | 21231M | 21477M (+1.16%) |
| mafft | 6772M | 6921M (+2.20%) |
| ClamAV | 13722M | 14000M (+2.02%) |
| lencod | 12818M | 13025M (+1.61%) |
| SPASS | 14455M | 14647M (+1.33%) |
| 7zip | 142937M | 143449M (+0.36%) |
| geomean | 18676M | 18982M (+1.64%) |
The cost of enabling the feature for builds with optimisations is quite reasonable given the improvements to the debugging experience, and there may be scope to reduce it further.
There’s a higher percentage hit for O0 builds, but I still think it’s worth enabling at O0. The feature modifies O0 debugging behaviour; if we enabled it with optimisations but not at O0 we would be providing a different baseline (O0) debugging behaviour. For example, a multi-line assignment might involve several back-and-forth jumps even at O0 without Key Instructions and is less likely to with Key Instructions.
(If you don’t care about implementation details or open questions, skip to the conclusion now)
Details
(Read the quick summary first)
Atoms having “one key instruction” is a simplification; this often isn’t true. Consider the following murky cases:
- loop unrolling in which an assignment’s Key Instruction store gets duplicated.
- Conditional branches in IR getting lowered to cond-br + br pairs.
- A front end may emit multiple stores for one variable assignment. Each is a candidate Key Instruction - they may get re-ordered by optimisations, so the front end can’t tell which it’ll be ahead of time. (In this case there is ony Key Instruction, but it’s not known until after optimisation).
Fear not, these cases can still all be handled (and are handled by our prototype).
Prototype implementation
The metadata - The two new DILocation fields are atomGroup and atomRank. Both are unsigned integers. Instructions in the same function with the same (atomGroup, InlinedAt) pair are part of the same source atom. atomRank determines is_stmt preference within that group, where a lower number is higher precedence. The default atomRank of 0 indicates the instruction isn’t interesting.
Pre-optimisation - A key-instructions pass sets the new DILocation fields on instructions that it deems important for stepping. The following instructions get atomGroup numbers: ReturnInst, SwitchInst, conditional BranchInst, MemIntrinsic, StoreInst. Calls are ignored here - they’re unconditionally marked is_stmt later.
For MemIntrinsic and StoreInst we additionally add the instruction computing the stored value, if there is one, to the same atom (we give it the same atomGroup number) with a higher atomRank (lower precedence). We do the same for the condition of the conditional BranchInst. This is so that we have a good “fallback” location if / when those primary candidates get optimized away.
During optimisation - Throughout optimisation, the DILocation is propagated normally. Cloned instructions get the original’s DILocation, the new fields get merged in getMergedLocation, etc. However, pass writers need to intercede in cases where a code path is duplicated, e.g. unrolling, jump-threading. In these cases we want to emit key instructions in both the original and duplicated code, so the duplicated must be assigned new atomGroup numbers, in a similar way that instruction operands must get remapped. There’s facilities to help this: mapAtomInstance(const DebugLoc &DL, ValueToValueMapTy &VMap) adds an entry to VMap which can later be used for remapping using llvm::RemapSourceAtom(Instruction *I, ValueToValueMapTy &VM). mapAtomInstance is called from llvm::CloneBasicBlock and llvm::RemapSourceAtom is called from llvm::RemapInstruction so in many cases no additional effort is actually needed.
mapAtomInstance ensures LLVMContextImpl::NextAtomGroup is kept up to date, which is the global “next available atom number”.
The DILocations carry over from IR to MIR without any changes.
DWARF emission - Iterate over all instructions in a function. For each (atomGroup, InlinedAt) pair we find the set of instructions sharing the lowest rank number. Typically only the last of these instructions in each basic block is included in the set (not true for branches - all branches of the same rank are included). The instructions in this set get is_stmt applied to their source locations.
Evaluation
I’ve modified dexter to plot debugging traces (those changes are out of scope of this RFC). Dexter drives a debugger, single stepping through requested function while recording the source location of each step. The line number of a step relative to the function start is plotted on a graph over “debugging steps” (i.e., discrete time). We do this for several different build configurations of the debug target, which enables us to compare the stepping behaviour at a glance.
I’ve drawn the traces by hand, for O2 and O2 with key instructions, on these two images:


Plotted on a graph, including an O0 trace (green) we get:
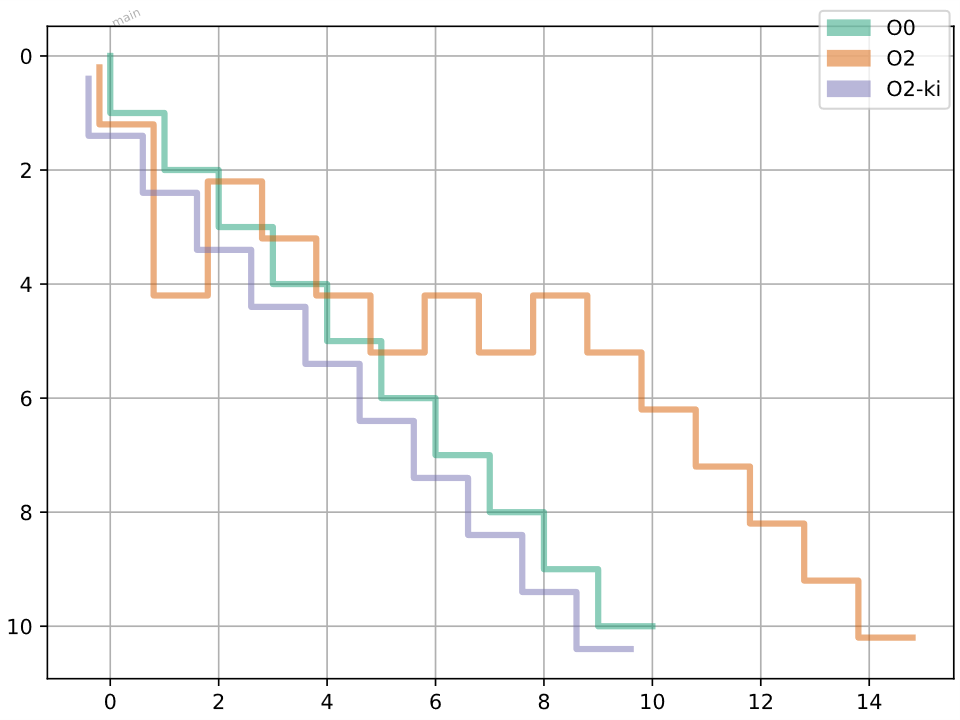
You can see there’ a lot of bouncing around at O2 (orange), in this case due to scheduling. The Key Instructions (purple) debugging behaviour matches the O0 (green) behaviour for this simple example.
I haven’t found a good quantitative measurement to evaluate this project, so my approach has been to generate and look at a number of these graphs and to manually step through “real” code, comparing debugging optimised code with/without the feature and at O0.
I’d like to share more of these graphs - I’ll aim to do so after the conference. Here’s a preview for now, on a trace from Lua, in which you can see another win for Key Instructions.

And another from Opensteer (inlined at O2 - and consequently at O2 with Key Instructions too, since the feature doesn’t affect optimisations):

These graphs demonstrate that Key Instructions reduces the complexity of stepping in “real” code. By removing unecessary noisy steps it makes the optimized stepping experience feel closer to an unoptimized experience.
Open question(s)
Q1 Should we use a pre-optimisation pass or have front ends apply the new metadata?
We currently use a heuristic-based approach to apply the new metadata in a pre-optimisation pass. An alternative would be for front ends to apply do it when creating the instructions (i.e., with new IRBuilder functionality).
Pros of current approach:
- Language / front end independent
- Simple & understandable; a small loop in one place
Cons of current approach:
- Some instructions’ DILocations are regenerated (setting the new fields), which is wasteful / slower than if the front end created them correctly (a significant portion of the O0 compile time increase)
- Front ends have limited or no control over what is considered “interesting”
I am not a front end engineer; without diving into it, I’m not sure how difficult it would be to implement that way.
In [DWARF] Specifying that a DILocation should be is_stmt=false @khuey points out that some front ends may (a) perform their own mandatory optimisations even at O0, which is relevant to the question above, and (b) may produce instructions which are undesirable for stepping (in the example in that thread, some constant variable initialisation isn’t desirable for users to step on at O0).
For (b) - this is easy to solve if front ends are responsible for applying the new metadata (simply don’t apply it to “uninteresting” instructions).
Otherwise, we’ll want a mechanism for the front end to convey that an instruction isn’t interesting. I think the approach proposed in that thread could work orthogonally alongside Key Instructions just fine. The idea is essentially to add a “never-is-stmt” bit to DILocations so the front end can exclude some instructions from stepping. At DWARF emission stage, the “never-is-stmt” bit would have precedence over Key Instructions. It’s just a matter of working out the best way to pack the new DILocation fields (and possibly think ahead for future fields).
There’s also the hybrid support option: we could provide the pre-optimisation pass and the tools for front ends to do it themselves. We could even start with one and migrate to the other.
That’s the only major question for me right now, but I’ll add any others brought up in the thread here.
Conclusion
Our prototyped changes to the compiler improve interactive debugging of optimized-code by reducing the impact of code motion and scheduling without affecting codegen or instruction source attribution.
We’d like to implement this in LLVM so we’re seeking general approval and would welcome any concerns and general thoughts.
References
- Key Instructions: Solving the Code Location Problem for Optimized Code (C. Tice, . S. L. Graham, 2000)
- Debugging Optimized Code: Concepts and Implementation on DIGITAL Alpha Systems (R. F. Brender et al)