Authors: Zachary Yedidia, Tal Garfinkel, Taehyun Noh, Shravan Narayan, Sharjeel Khan, Pirama Arumuga Nainar, Nathan Egge
This RFC proposes adding Lightweight Fault Isolation (LFI) backend compiler passes and LFI-specific targets to LLVM. These changes primarily touch the MC layer of LLVM, the AArch64 and x86-64 backend, and the Clang driver.
Overview
Memory safety bugs in native code (C/C++/Assembly) constitute a majority of critical software vulnerabilities. Sandboxing is a compelling way to mitigate these bugs as it offers strong security properties, without the engineering costs of rewriting existing code in a different (memory safe) language.
Unfortunately, process based sandboxing can impose significant overheads that limit its utility. In-process sandboxing, can avoid some of these overheads (e.g. context switches in 10s of cycles vs. 1000s). However, WebAssembly—the only widely available in-process sandboxing technology— makes significant performance and compatibility compromises. These compromises make sense for the Web, where properties like platform independence are important. However, it limits its utility for sandboxing in other settings.
Lightweight Fault Isolation (LFI) is a lower level approach to in-process sandboxing that prioritizes performance and compatibility with existing code (and tools)—to support sandboxing existing C/C++/Assembly code with minimal performance overhead and engineering effort. Here we present the motivation, design, details on current implementation and performance, and plans to upstream and support LFI.
Use Cases at Google
Google has an enormous amount of third party and first party C/C++ code where memory safety is a primary concern. For example, third-party native libraries are a frequent source of critical security issues in Android. Many libraries have not been sandboxed due to process overheads, while others have been sandboxed using processes, but IPC overheads impose a significant tax.
For example, Android currently uses a sandbox process for media codecs. However, IPC overheads impose roughly a 50% overhead for audio encoding (e.g. libopus). LFI offers us a practical path to addressing these problems of security and efficiency. Eventually, we hope to make this technology available to Android applications developers who often rely on native libraries. We are also exploring LFI to mitigate bugs in third-party device drivers, which constitute the large source of local privilege escalation vulnerabilities in Android.
There has been significant interest from teams at Google, and multiple teams are supporting engineers who are already contributing to LFI’s development.
Our conversations with teams at large software and hardware companies outside of Google suggest the capabilities that LFI offers are compelling for many teams looking to harden third-party and first-party code at low cost.
Why LFI
Limitations of Process Sandboxing
The reliance of process-based sandboxes on the OS limits performance and flexibility in a number of ways. To start, OS context switches are often several orders of magnitude more expensive than function calls. Not only does this result in high IPC overheads, it scales poorly as the number of sandboxes per-core increases. In contrast, an LFI context switch is on the order of tens of cycles, very close to a normal function call. The memory overhead of processes can also be a limiting factor as the number of sandboxes scale.
Processes are also expensive to startup and destroy, which limits their utility for short lived sandboxes. Unsurprisingly, in-process sandboxing technologies like WebAssembly and eBPF have gained significant traction in settings like serverless and data plane extensibility (e.g. Envoy) where minimizing these overheads are critical. Finally, processes are entangled with the existing OS model of parallelism, concurrency, and resource management–which can make it difficult to retrofit process sandboxing in existing applications without (sometimes significant) refactoring.
In contrast, with LFI, context switches and IPC can also be close to that of a normal function call, removing scaling and IPC limitations, and per-sandbox memory overheads are minimal. LFI isolation is also orthogonal to parallelism and concurrency, making it possible to create an LFI sandbox per-thread, per-coroutine, or per-library, or have multiple threads or co-routines that all use the same sandboxed library. All these factors can make it easier, and more efficient, to add sandboxing to existing applications.
Limitations of WebAssembly
In recent years, part of our team has used WebAssembly to deploy sandboxing for third-party libraries in Firefox, and relied on it extensively in other research. We found that WebAssembly’s higher level, platform independent approach to sandboxing—while valuable in settings such as the Web—also requires significant trade-offs in performance and compatibility. These trade-offs limit its utility for sandboxing C/C++/Assembly code in existing applications where maximizing performance and minimizing engineering effort are the primary concerns.
To touch on some examples: Wasm cannot support handwritten platform specific assembly code, and its SIMD support is extremely limited, making it impractical to use for sandboxing high performance media codecs, and less than ideal for compression libraries, numerical code, cryptography, etc. that often depend on hand written assembly or platform specific intrinsics. Wasm’s requirement for precise traps (for determinism) preclude the use of many SFI optimization techniques that rely on masking and truncation. We can see these differences in performance, for example, we see a 3x-10x reduction in overhead for LFI ARM64 vs. state-of-the-art Wasm compilers (wasm2c, WAMR, and Wasmtime). Wasm also does not attempt to support existing libc’s (e.g. bionic, glibc), much of the linux system call API, relies on a different ABI (different pointer sizes), and breaks compatibility with many existing tools such as ASAN, TSAN, perf, debuggers, etc.
Design
Lightweight Fault Isolation (LFI) aims to support low level software sandboxing with minimal extra constraints. LFI eschews platform independence, and gives the compiler and runtime maximum freedom to exploit platform specific hardware or novel optimization techniques. At the same time, LFI tries to adhere as closely as possible to the existing target ABI and binary conventions (e.g. ELF and Dwarf specifications) with a few caveats (e.g. reserve registers) to maintain compatibility with existing code and tools.
Minimizing performance overhead is often what determines whether or not sandboxing can be deployed. Thus, LFI aims to give developers control over performance vs. security trade-offs, and to make use of hardware specific features when available. For example, developers can choose between full sandboxing (loads/stores/jumps), or stores-only (stores/jumps) sandboxing that provides integrity. LFI also supports MPK (jumps) which provides hardware support for zero cost sandboxing of loads and stores.
Compatibility is also critical for adoption. LFI can support nearly all existing C/C++/Assembly code without source modifications. This includes media codecs, compression libraries, etc. that can rely on tens or even hundreds of thousands of lines of handwritten assembly. Further, as LFI simply adds some additional instrumentation (like any other compiler pass), and doesn’t require deviating from normal dwarf or elf conventions, interoperability with existing debuggers and profiles can be seamless.
LFI also aims to be simple enough to enable high assurance compiler and runtime implementations. For the compiler, we are able to check that LFI based instrumented binaries are correctly sandboxed with a small stand-alone verifier.
LFI today
Our current LFI implementation supports both ARM64 and x86-64 processors. Since LFI sandboxes are in-process, sandbox context switches are just 10s of cycles, often ~100x faster or more than process-based sandboxes.
LFI’s closer to the metal approach offers a 3x-10x reduction in sandboxing overheads vs. state-of-the-art Wasm toolchains. On Spec2017, it incurs roughly 7% overhead on AArch64 vs. native code for full sandboxing, and 2% overhead when only sandboxing writes (providing integrity but not secrecy).
LFI is neutral to the system call/library interface, thus we are able to support both unmodified libraries (using the linux system call interface) and device drivers through the use of different runtimes.
The core of LFI consists of two parts: (a) a compiler pass implemented in LLVM that restricts memory accesses to within a sandbox by adding trampolines and rewriting assembly and (b) a runtime environment for libraries that restricts system call access. Our project also has several FFI tools (RLBox, lfi-bind) to enable easy and safe use of sandboxed libraries.
At present, we are only aiming to upstream the LLVM compiler changes for LFI (a). However, the runtime and other LFI components are all being developed under an open source license, and we are open to upstreaming other parts at a later stage if there is community support for making LFI a stand-alone Clang/LLVM tool.
LFI Design Details
We provided a section to explain the general LFI sandboxing scheme then explain the exact LLVM implementation with some results from our experiments.
LFI uses an architecture-specific sandboxing scheme designed to minimize performance overhead and maximize compatibility. In general, it relies on a combination of classical and modern software based fault isolation (SFI) techniques.
Sandboxed programs are restricted to a 4GiB portion of the virtual address space, within which all of their code and data (heap, stack, globals, etc…) must reside. Code pages are mapped non-writable, and data pages are mapped non-executable. The sandbox may not access any memory outside of its 4GiB region, and may not directly interact with the host OS (no system call instructions). Instead, it must perform runtime calls to have the trusted runtime environment interact with the host OS on its behalf.
When targeting LFI, the compiler must produce only instructions that are verifiably safe (i.e., guaranteed to not access memory outside the sandbox). Internally, this is implemented by rewriting a subset of machine instructions into one or more safe instructions. For the sake of exposition, we will focus on the AArch64 version here.
To start, LFI reserves a few registers to hold frequently used variables. We reserved the highest callee-saved registers since those are the least likely to be used in hand-written asm. On AArch64, x27 stores the base virtual address of the sandbox (the start of the 4GiB accessible region), and x28 may only contain valid sandbox addresses (addresses within the 4GiB accessible region). Here are some example rewrites:
//sandbox ldr by taking bottom 32-bits of x1, adding the sandbox base(x27)
ldr x0, [x1]
->
ldr x0, [x27, w1, uxtw]
//similar, but use add to first "guard" x2, then do the ldp
ldp x0, x1, [x2]
->
add x28, x27, w2, uxtw
ldp x0, x1, [x28]
The LFI AArch64 target uses a standard LP64 ABI, even though accessible memory is restricted to 4GiB. This maintains compatibility with host code, allowing structure definitions to be shared between the host and the sandbox. The 64-bit ABI also allows us to support stores-only sandboxes (more on that in the performance section).
Rewrites are applied to the following types of instructions:
-
Memory accesses through non-sp registers.
-
Indirect branches.
-
Modifications of the stack pointer (sp must always contain a valid sandbox address).
-
Modifications of the link register (lr must always contain a valid sandbox address).
-
System calls.
-
Thread-local storage access (reads/writes of
tpidr_el0).
These rewrites allow us to compile many existing libraries (including musl libc and libc++), as well as those with large bodies of hand written assembly code (e.g. libdav1d) for LFI without any modifications.
LLVM Implementation
There are two primary changes needed in LLVM to support LFI: a new target for LFI, and the LFI rewriter implementation in the MC backend.
LLVM Target
Conceptually, LFI is a new architecture subset, implemented as a “sub-architecture” similar to ARM64EC. For AArch64, LFI is enabled by using the aarch64_lfi architecture. A typical complete LFI target triple looks like aarch64_lfi-unknown-linux-musl. aarch64_lfi defaults to the load and stores LFI mode but you can change the mode by selecting specific subtarget features. For example, you can select stores-only LFI mode by enabling the +lfi-stores feature or control flow/jumps-only by enabling +lfi-jumps (for use in combination with memory protection keys or other hardware-based memory isolation). We also considered using the vendor field (aarch64-lfi-linux-musl), or enabling LFI via a flag (-fsanitize=lfi), but we believe that using a sub-architecture is the best approach.
LLVM MC Rewriter
The LLVM implementation of LFI is based on the Native Client (NaCl) auto-sandboxing assembler, which has been maintained out-of-tree at Google for ~10 years to continue support for the deprecated NaCl project, and served as a robust approach that required minimal development effort to keep functional.
In the LLVM MC layer, the MCStreamer class is responsible for emitting MCInst instructions to object code or textual assembly. We define a new MCLFIExpander class that performs LFI’s instruction rewrites during this emission process. MCStreamer is modified to have an MCLFIExpander, and, if enabled, passes the MCInst it would like to emit to the expander’s expandInst virtual method, which performs any necessary rewrites and emits new instructions. The actual expansion is performed by an architecture-specific subclass of MCLFIExpander – for now this is just AArch64MCLFIExpander and X86MCLFIExpander.cpp.
Performing rewrites at the assembler level is critical for compatibility and robustness. It allows us to transparently handle a large amount of hand-written and inline assembly (common in media codecs and in runtime libraries like libc, libc++, compiler-rt, libunwind, etc…).
Optimizations
The basic rewriter expands unsafe instructions on a per-instruction basis, without any further analysis of the surrounding instructions. This can lead to suboptimal performance due to redundant or unnecessary guards. Here are some examples of further optimizations:
- Basic guard elimination: if the same register is guarded multiple times in the same basic block, without intervening modifications to the register, the later guards can be removed. A prototype of this optimization is implemented by modifying the MCStreamer to notify the MCLFIExpander when basic blocks begin and end, allowing the expander to track whether a guard is redundant with another in the same basic block.
- Guard hoisting (Future Work): if a register is guarded inside a loop body, but the register is not modified in the loop body, the guard may be hoisted outside of the loop. For more aggressive hoisting, additional register(s) can be reserved specifically for hoisting. A prototype of this optimization is implemented via a Machine IR backend pass that inserts new directives to inform the MCLFIExpander of regions where guards are not necessary and a hoisting register should be used instead.
- Stack guard elimination (Future Work): if the stack pointer is modified by a small constant offset and in the same basic block the stack pointer is accessed via a memory instruction, the guard on the modification may be removed. We do not currently have a prototype of this.
In general, the expander itself is too low-level to perform the analysis needed for optimizations. As a result, our approach to optimizations is to do the analysis in a MIR backend pass, and insert directives/metadata that is used by the expander to customize how guards are emitted. As a result, these optimizations only apply to code generated by LLVM, and not to hand-written or inline assembly. It is important to note the rewriter runs after relaxation, so relaxation must conservatively estimate the expansion and these optimizations would reduce the number of expanded instructions.
X86-64 Support
LFI also supports a sandboxing scheme for x86-64. The overall approach is similar to AArch64, using a 4GiB sandbox with MC-level rewrites, but the low-level scheme is architecture-specific, leading to differences between the two. In particular, there are two main differences:
-
Since x86-64 supports variable-length instructions, restricting control-flow from jumping into the middle of an instruction requires either instruction bundling, or hardware CFI (i.e. CET IBT). Our current implementation uses bundling (support in LLVM for bundling was originally developed for Native Client) since it is relatively low-overhead (~4%) and does not require hardware or OS support. Bundling support was recently removed from LLVM’s generic MC layer, and the maintainer has recommended that it be reimplemented in the X86 backend instead.
-
On X86-64, LFI uses Segue, an optimization that exploits the remaining support for segment relative addressing in x86-64 the
%fsand%gssegment registers, which may be used as the base for a memory operation, but do not enforce bounds. However, LFI can still make use of segment registers to make memory accesses safe, since segment registers can be used to express an addressing mode with an addition between a 64-bit and 32-bit value. This is the exact guard operation needed by LFI – an access such asmovq (%rax), %rdiis transformed intomovq %gs:(%eax), %rdi, where%gsstores the base of the sandbox.%fsis used as the TLS base in the Linux x86-64 ABI, but%gsis unused. For platforms where no segment register is free (Windows), we can fall back to a scheme that only uses general-purpose registers (similar to the original Native Client SFI scheme, but with a 64-bit ABI).
LFI Runtime
A binary built for the LFI target runs within the “LFI runtime,” which can be thought of as an emulator. The runtime is responsible for loading the binary, running verification, initializing registers with appropriate values (i.e., x27 with the sandbox base), and handling transitions in/out of the sandbox. The runtime services three types of runtime calls:
- “System calls:” currently we build LFI binaries for a Linux target, allowing programs to make system calls according to a Linux API. During compilation, the actual system call instructions are rewritten into runtime calls that perform a “system call” operation. These are serviced by the LFI runtime, which provides a subset of the Linux API, and can block certain system calls, or apply a more fine-grained system call restriction policy.
- TLS reads: reads of
tpidr_el0are rewritten by the compiler into runtime calls, which load the sandbox’s TLS base. The runtime emulates the sandbox’s TLS base, meaning thattpidr_el0is not modified when transitioning in/out of the sandbox. This is desirable for compatibility and performance (especially on x86-64, where modifications of%fsare quite costly). - TLS writes: similar to TLS reads, writes to
tpidr_el0are rewritten by the compiler into runtime calls.
The sandbox uses an indirect branch to invoke runtime calls, whose code is located outside the sandbox. The indirect branch sequence for runtime calls loads from a specific known location where the runtime call entry points are stored. This location can be configured, but by default is the page before the start of the sandbox. Loading the entrypoint pointer uses a ldur instruction with a negative offset from the sandbox base register (x27). Other options include using the first page of the sandbox (the original approach), but this is undesirable because null pointer accesses will be masked to this location, or using the second page of the sandbox.
When using LFI for library sandboxing, the library is built with the LFI compiler, along with all its dependencies, into a static ELF binary. The host application uses the LFI runtime as a library to load the binary, and then may invoke individual functions inside it, similar to inter-process calls with a process-based sandbox, except without the IPC and synchronization overheads. Readers may also be familiar with WebAssembly, which uses a similar architecture: the compiler produces a binary for the WebAssembly target, which is then run within a WebAssembly runtime that may be linked with a host application.
Using LFI
Using LFI to sandbox a library involves changing how the library is built, and how the library is invoked by the application. The first step is to build the library for the LFI target – often this just involves changing the compiler used for the library build. Next, the LFI compiler is used to create a static ELF executable from the library that includes all its dependencies. This binary contains all code and static data that will be available in the sandbox.
On the host side, the application must be modified to use an FFI-like interface for invoking library functions. We have a tool called lfi-bind designed for C/C++ (host) to C (sandbox) invocation, as well as support for LFI in RLBox, a tool for C++ to C library sandboxing. Trampolines are automatically generated for each exported function, which transition in/out of the sandbox by saving and restoring the appropriate registers and state. Buffers passed into the sandboxed library must be within the sandbox, which often involves changing how they are created to use a special sandbox allocator that allocates memory from within the sandbox. Inputs received from the sandbox must be validated before use (e.g., pointers returned by the library). RLBox provides type-based compile-time enforcement that proper validation exists, and in the future, we’d like to investigate augmenting lfi-bind with static analysis tools that can provide similar guarantees when the host code is written in C rather than C++.
Current Performance
We compiled LFI with SPEC 2017 benchmarks on Apple M2 and AMD Ryzen 9 7950X alongside some Media codecs like libopus or libdav1d on Pixel 9. We ran the Media Codec by pinning them to the three different types of cores in Pixel: small, medium, and big. The cores’ processing speed increases when you go from the small core to the big core. The increased processing speed causes the overheads to decrease. You can see the results below and we summarize the results in the caption.
We profiled three different modes for LFI: LFI (full sandboxing), LFI-stores (sandboxing stores and control flow–loads unsandboxed), and LFI-jumps (only control flow sandboxed). As discussed, LFI offers the strongest isolation, LFI-stores offers only integrity—which is still useful in many situations and gain significant performance by removing load instrumentation, and LFI-jumps—which is useful in combination with hardware features like Intel MPK which can be leveraged for load/store sandboxing.

SPEC 2017 benchmarks on Apple M2 had a geometric performance mean of 6.9% for full sandboxing mode and 1.6% for stores only mode, and 0.9% for jumps mode.
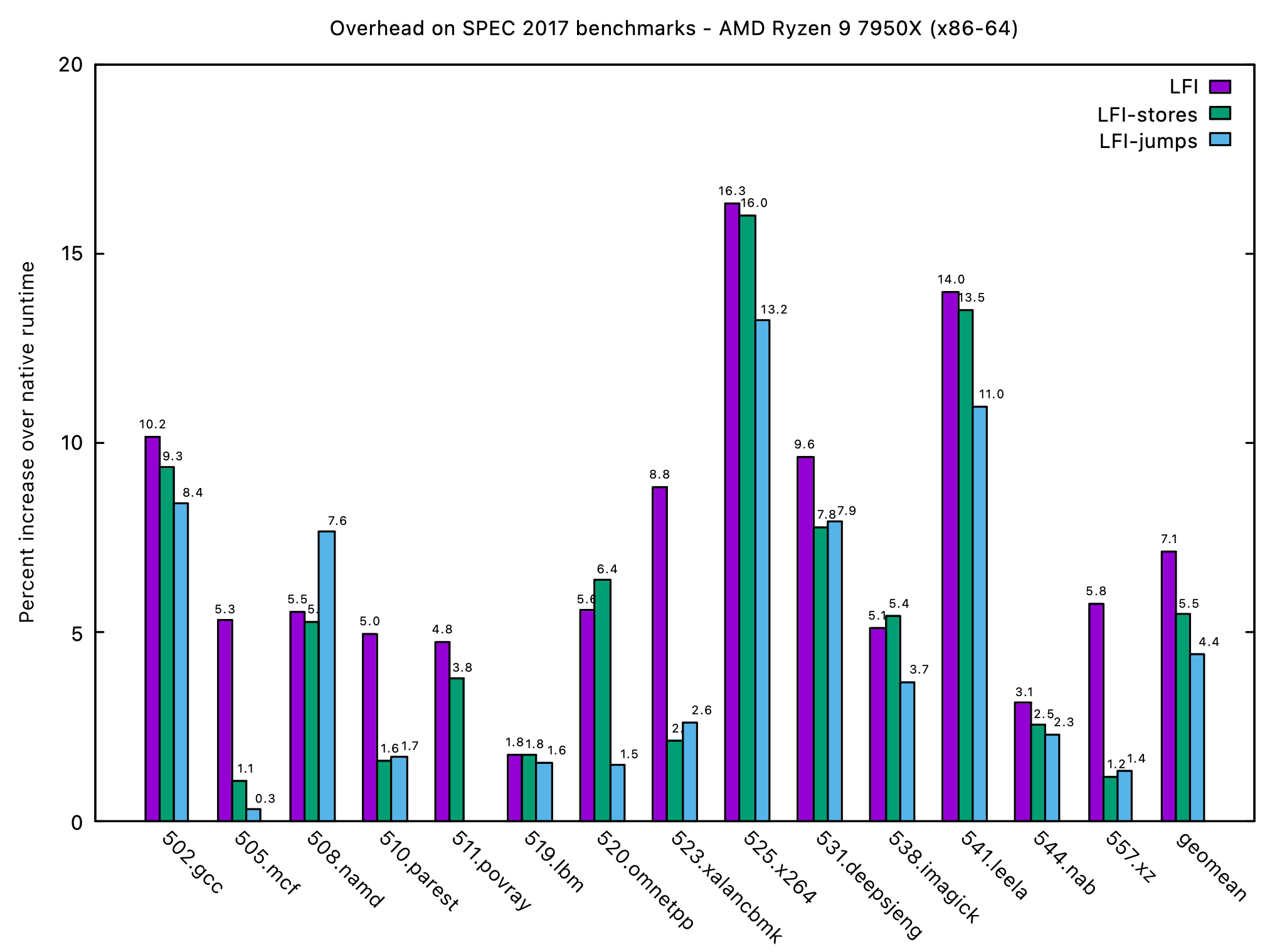
SPEC 2017 benchmarks on AMD Ryzen 9 7950X had a geometric performance mean of 7.1% for L/S mode and 5.5% for stores only mode, and 4.4% for jumps mode. This added overheads on x86-64 is due to the cost of bundles.

Libopus was used to decode a giant file on Pixel 9 and we saw a geometric performance mean of 10.77% for L/S mode and 2.92% for stores only mode.

Libdav1d has many assembly files so it was a stress test for LFI. We saw a geometric performance mean of 6.58% for L/S mode and 1.93% for stores only mode.
Upstreaming and Ongoing Maintenance Effort
Our AArch64 LLVM LFI compiler changes are at lfi-project/llvm-project and we plan to upstream these changes first. These AArch64 changes are around ~4 KLOC being added to upstream LLVM and a majority of it is in LLVM backend.
As for x86-64, our current implementation is based on the original bundling implementation that has been removed in LLVM. We are already working on a new implementation for bundling in the x86 backend based on the recommendation of the maintainer who removed the original version. Once this new bundling is stable, we plan to upstream the x86-64 compiler changes alongside the newly implemented bundling in the next phase.
We have consulted many LLVM contributors on best practices, and tried our best to separate the LFI passes so we do not make it harder on current maintainers. If needed, we are ready to split the changes into smaller PRs so it is easier for reviews. We are committed to the ongoing support, maintenance, and development of the LFI project including the compiler passes in LLVM. We will adhere to the rules mentioned in LLVM’s Developer Policy for new targets.
As mentioned previously, we are only planning to upstream the LLVM compiler changes for LFI at this time. An LFI runtime and other tools are available as part of the open source lfi-project.
Extra Resources
We gave a talk about LFI at the Qualcomm Product Security Summit 2025 so you can find more information in the slides. In addition, we are giving a talk about LFI at this year’s LLVM Developers Meeting on Tuesday, October 28th at 11 AM.