The Clang analyzer is capable of CTU analysis by importing definitions of
functions from other translation units. CodeChecker users have been using CTU
since 2018, and we repeatedly receive these major critiques:
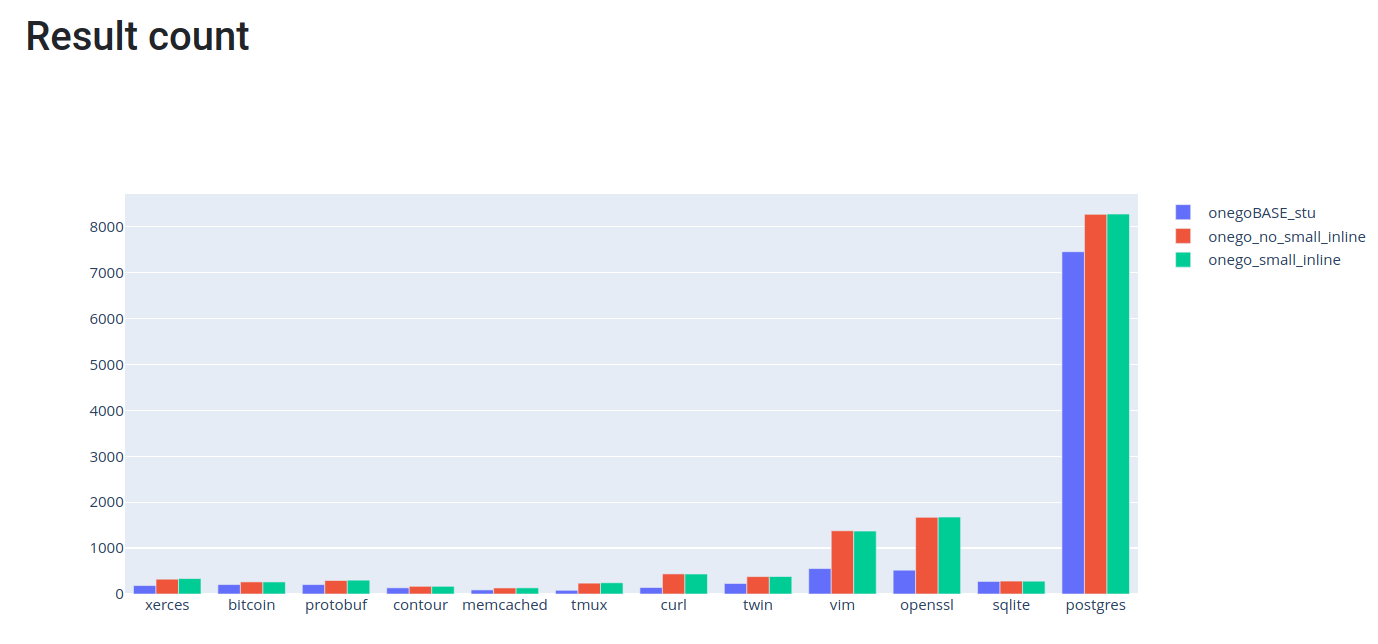
- CTU analysis is slow. Indeed, the slowdown is usually around 2x-5x in case
of C projects (compared to the single TU analysis). The slowdown can be up-to
10x-12x in case of a more complex C++ project (e.g. protobuf). - CTU is loosing bug reports, compared to the single translation unit
analysis. Because of the loss of results, users most often run BOTH the single
TU and the CTU analysis.
To address these issues, we have been working on an alternative CTU
implementation, which we are planning to upstream soon.
The new implementation is the natural extension of the normal single TU
analysis. The approach consists of two analysis phases. During the first phase,
we do a normal single TU analysis. During this phase, if we find a foreign
function (that could be inlined from another TU) then we don’t inline that
immediately, we rather mark that to be analysed later.
When the first phase is finished then we start the second phase, the CTU phase.
In this phase, we continue the analysis from those points (exploded nodes)
which had been enqueued during the first phase. We gradually extend the
exploded graph of the single TU analysis with new nodes that are created by the
inlining of foreign functions.
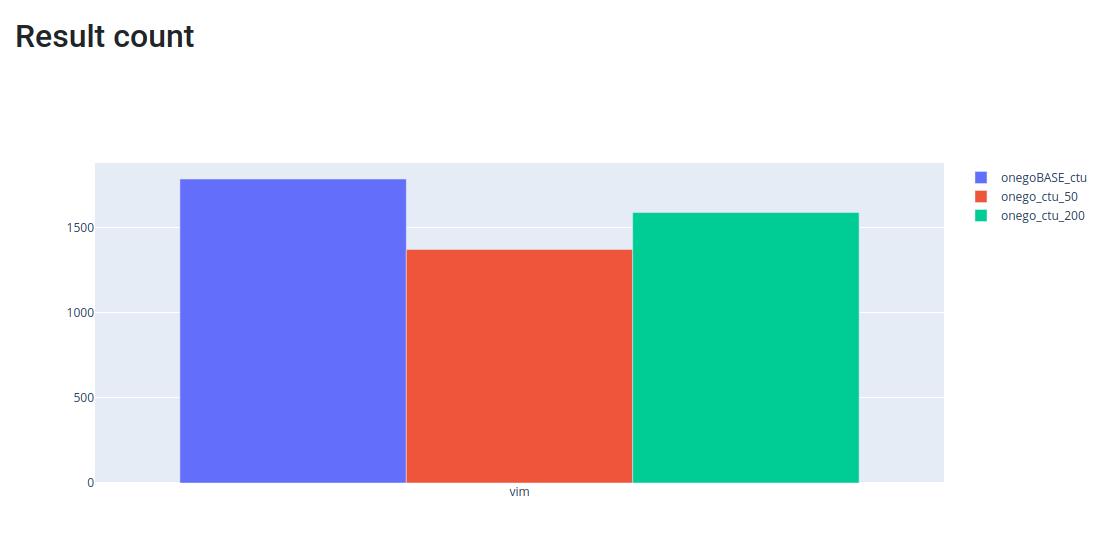
We count the number of analysis steps of the first phase and we limit the
second (ctu) phase with this number. Measurements show that we can keep the
slow-down most of the time around 2x even in case of complex C++ projects. We
may loose not more than 2% of the bug reports, compared to single TU analysis.
These lost reports stem from the fact that the AST is extended from foreign TUs
and these lost reports are false positives. Compared to the original CTU,
however, we may loose roughly 25% of the bug reports; this is the trade-off
that we take to constrain the runtime down to 2x.