Summary
This post introduces the current implementation of RegionStore and it’s limitation about storing the extents of a binding. After that it describes a possible solution to tracking the extent and shows how it would be implemented and the results from an experimental implementation.
RegionStore
The current implementation of RegionStore stores the SVals based on their base MemRegion and their offset inside that region. This means that these two values uniquely identify the corresponding SVal.

An llvm::ImmutableMap<const MemRegion *, ClusterBindings> is used to store the bindings, where the const MemRegion * is the base region of the variable and ClusterBindings is an llvm::ImmutableMap<BindingKey, SVal>. BindingKey consists of the base region, the offset and the type of the binding, which can either be Direct or Default.

Every MemRegion is assigned a cluster, which will store the SVals inside that region based on their offset from the region base address. If a region doesn’t have an existing cluster, a new one will be created for it, moreover one region can only have one cluster assigned to it at a time.
RegionBindingsRef RegionBindingsRef::addBinding(BindingKey K, SVal V) const {
const MemRegion *Base = K.getBaseRegion();
const ClusterBindings *ExistingCluster = lookup(Base);
ClusterBindings Cluster =
(ExistingCluster ? *ExistingCluster : CBFactory->getEmptyMap());
ClusterBindings NewCluster = CBFactory->add(Cluster, K, V);
return add(Base, NewCluster);
}
Bindings
int x = 1;

struct S {
int a, b, c;
};
S s;
s.a = 1;
s.c = 3;

As it’s seen, a cluster contains mappings of values to specific points of memory. In the examples above all of the values are directly assigned to a location in memory, so the mappings can be considered Direct bindings.
There are however scenarios when instead of directly assigning values to specific locations, a larger portion of memory is set (e.g.: by calling memset). In such cases a Default binding is created. Since a Default binding affects the whole cluster, one cluster can only contain one Default binding at a time (since in the current implementation a Default binding is always in the form BaseReg + 0 -> Val, whenever a new one is created, the previous one is overwritten). Also there are some values such as LazyCompoundVal that can only appear as a Default binding, which has been ensured by D132143.
S s;
memset(&s, 0, sizeof(s));

S s;
memset(&s, 0, sizeof(s));
s.a = 1;

Note that
Direct and Default bindings can appear together in the same cluster as seen in the example above, where the cluster contains both of them at the same location.
Lookup
Looking up a binding inside a cluster happens based on the BindingKey, which stores the region, the offset and the type of the binding, thus ensuring a Default binding is not going to be found if the caller is looking for a Direct binding.
const SVal *RegionBindingsRef::lookup(BindingKey K) const {
const ClusterBindings *Cluster = lookup(K.getBaseRegion());
if (!Cluster)
return nullptr;
return Cluster->lookup(K);
}
Whenever the analyzer is interested in a specific value, it will try to look for a Direct binding first and if it’s not found, a Default binding will be searched for the region instead.
SVal RegionStoreManager::getBindingForVar(RegionBindingsConstRef B,
const VarRegion *R) {
if (std::optional<SVal> V = B.getDirectBinding(R))
return *V;
if (std::optional<SVal> V = B.getDefaultBinding(R))
return *V;
// Handle if none of them is found.
...
}
S s;
memset(&s, 0, sizeof(s));
s.a = 1;
int x = s.a;
int y = s.b;

Limitations
While the current implementation is suitable for modelling most of the variables throughout the analysis, there are some edge cases, like this infamous one below, which caused the analyzer to hide some true positive bug reports.
struct Point {
int x;
int y;
int z;
};
struct Circle {
Point origin;
int size;
};
Point makePoint(int x, int y) {
Point result;
result.x = x;
result.y = y;
result.z = 3;
return result;
}
void issue() {
Circle testObj;
memset(&testObj, 0, sizeof(testObj));
testObj.origin = makePoint(1, 2); <-- problem caused by this line
int x = testObj.size;
}
This is how the bindings look like at the moment of the assignment in the marked line:

At
testObj.origin = makePoint(1, 2); the temporary object will be assigned to testObj + 0, however since the temporary object is a lazyCompoundVal, which can only be a default binding, Default: testObj + 0 -> 0 will be replaced by Default: testObj + 0 -> lazyCompoundVal{result, ...}.

Later when testObj.size is read, instead of returning 0, some other value will be returned falsely. In the past it used to be Undefined, as it can be seen in the commit that addressed it. In the same commit it can be seen that the solution was to prevent the analyzer from reading Undefined from a lazyCompoundValue and pretend that the read value is Unknown, which will hide every other cases, when the value is really Undefined and a warning should be reported.
There are also scenarios where Direct bindings trick the analyzer into reading a wrong value.
void foo() {
char x = 0;
int y = *((int *)&x);
}

Here the analyzer is going to assume that
y is 0, however in reality it is an Undefined value.
Solution
It has been pointed out by a FIXME inside RegionStoreManager::getLazyBinding() and @NoQ also told me before that the proper solution is to change RegionStore so that it also tracks the extent of the binding instead of just the region and the offset. Throughout the following sections I would like to describe the way I found to achieve this.
BindingKey
BiningKey would also store the extent and use it for comparrison. Two BindingKeys would be equal if they had the same region, kind, offset and extent.
class BindingKey {
...
uint64_t Extent;
...
explicit BindingKey(..., uint64_t extent);
...
bool operator==(const BindingKey &X) const {
return <old operator== implementation> && Extent == X.Extent;
}
};
MemRegion
MemRegion would be modified so that it also knows about it’s extent. The extent would be calculated lazyly based on the type of the region except for some special cases that need additional handling, like bitfields.
If we fail to find the extent for some reason and we can’t reason about it, we pretend that it’s infinite as it happens in the current implementation. The same pretense is made, when the calculated extent is 0, which can happen when something is assigned to a placeholder variable.
struct hh {
char s1[0];
char *s2;
};
memcpy(h0.s1, input, 4);
h0.s1 doesn’t exist in memory and it’s extent is 0. In this particular case the extent could be determined from the parameter of memcpy, but this change is not in the scope of this proposal. From the MemRegion’s point of view, it cannot be told how wide the region is.
ClusterBindings
ClustedBindings are currently llvm::ImmutableMap<BindingKey, SVal>s, but this would change so that they are derived from this map and provide two additional lookup methods for partial and overlapping value lookup.
class ClusterBindings : public llvm::ImmutableMap<BindingKey, SVal> {
const SVal *lookupPartial(const BindingKey &K) const;
std::vector<SVal> getValuesCoveringBinding(const BindingKey &K) const;
};
The default lookup(), which is inherited would provide a quick O(log(n)) way to lookup the exact binding if it exists, while lookupPartial() is a slower O(n) method that can lookup overlapping bindings and getValuesCoveringBinding() is the slowest O(n * log(n)) method which can be used to tell if the binding is covered by initialized values or not.
Lookup
There can be multiple scenarios that could occur during a lookup. The first is when the exact same region is looked up.
int x = 10;
int y = x; <--

Since the binding being looked up and the binding in the store overlap completely, the default
lookup method will be able to automatically find the corresponding value, there is no need for manual work.
There is a differece however in this next scenario, when a small part of an existing binding is looked up:
int x = 1024;
char y = *((char *)&x); <--
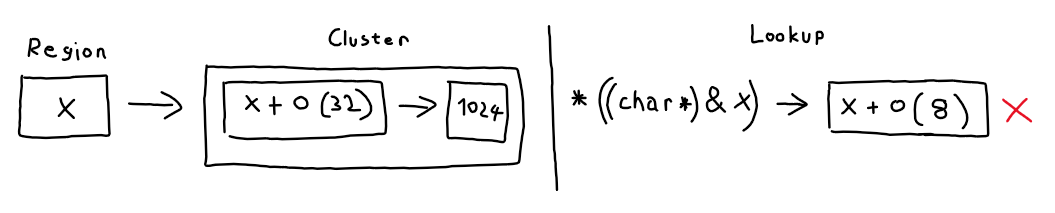

The current implementation of RegionStore would return 1024 in this case, because it ignores the extents, which is incorrect as (on a little endian paltform) the last byte of x is being assigned to y, which is 0. With the proposed changes RegionStore would not find a direct binding by calling lookup, however calling partialLookup would find this region that overlaps the binding and would return 1024.
The third case the could happen is when the looked up binding overlaps every stored binding.
char x = 10;
int y = *((int *)&x);


Here the current implementation finds the binding and returns
10, which is also incorrect becuase the other 3 bytes past x have not been initialized (technically those bytes would be the part of some other variable on the stack, or the stored base pointer, etc. however in the static analysis context those are still uninitialized values). In this case partialLookup wouldn’t find the binding either.
The partialLookup method
This method finds the smallest binding that overlaps the looked up binding. In the example below the value of Binding 2 will be returned.
int x = 1024;
*(short *)((char *)&x + 1) = 0;
int y = *((char *)&x + 2); <--

If the looked up region is not overlapped by any other regions, this method will not return any value.
struct S {
char a;
char b;
char c;
char d;
};
void foo() {
S s{1, 2, 3, 4};
int x = *(int *)&s; <--
}

In this case none of the regions overlap the binding, but the binding overlaps multiple regions. The current implementation would return
Binding 1, which is incorrect and as seen, this case cannot be solved with partial lookup either. If only default and partial lookup existed in this example we would find that x has been assigned a garbage value, which is also incorrect. This is why getValuesCoveringBinding() has also been added.
The getValuesCoveringBinding method
This method returns the SVals that overlap the binding being looked up. If the binding is not covered fully by initialized values, an empty std::vector<SVal> is returned. In the example at the end of the previous section, the vector would contain Binding 1, Binding 2, Binding 3 and Binding 4. This will be useful if in the future we decide to concatenate these values.

In this next example however an empty vector is returned:

Strategy
Looking up a value would change the following way:
// Try getting the binding by comparing everything.
if getDirectBinding(region):
return binding;
if getPartialBinding(region, direct):
// We found the part of a symbolic region.
if binding.isSymbolic():
return getDerivedRegionValueSymbolVal(bindingSymbol, region);
// We found the part of a constant value, but SVal slicing is
// not supported.
if binding.isConstant():
return UnknownVal();
// The bindig is covered by initialized values,
// but concatenating them is not supported.
if !getValuesCoveringRegion(region, direct).empty():
return UnknownVal();
if getDefaultBinding(region):
return binding;
// The idea of a default binding is that every
// value that doesn't have a direct binding inside
// the cluster is covered by it.
if getPartialBinding(region, default):
return binding;
Results
The proposed changes have been implemented in D132752 and multiple false positives in our regression tests have been corrected so far. The only known true positive that disappeared is coming from the UninitializedObjectChecker, however after analyzing it, I think this comes from the checker and not the RegionStore model.
Thoughts and feedbacks are appreciated.