What is OpenACC?
OpenACC is a standardized, directives-based parallel computing language extension which permits easier targeting of CPU and GPU devices. OpenACC has programmers provide instructions in the form of pragmas (in C and C++) to the compiler for how to optimize, parallelize, and offload code. OpenACC was designed from the ground-up for heterogeneous computing, with all of the individual directives targeted at the problems and solutions that best apply to accelerators. OpenACC takes a descriptive approach to parallelization, enabling compilers more freedom in how to parallelize for a given architecture than other approaches, while providing the ability for programmers to optimize through progressively more prescriptive clauses.
Other Implementations
There are currently multiple implementations widely available of OpenACC, including one that is currently in process. First, the NVIDIA HPC C++/Fortran compilers 1 are both extremely mature OpenACC implementations. GCC 2 has support for OpenACC, with experimental support available as of GCC5, and a mature implementation available as of GCC9. Additionally, the Flang 3 project has recently started their implementation of OpenACC. Finally, a DoE project known as CLACC 4, a Clang/LLVM based OpenACC->OpenMP translator, has implemented OpenACC, albeit with limited use. While the Cray Fortran compiler also supports OpenACC, support for OpenACC was dropped from their C/C++ compilers when the Clang front-end was adopted. However, based on comments during Supercomputing 2022 they would be interested in regaining OpenACC support in these compilers if support were added to Clang.
The proliferation of implementations available show an extensive interest in OpenACC, which I believe makes it a good idea for Clang to implement it as well.
Implementation Strategy
Much of the implementation has already been designed by the Flang community, so we intend to leverage as much of the infrastructure developed there as possible. We are confident that the two compilers can share runtime and code generation facilities, which will greatly simplify both implementations.
However, one consideration is the OpenACC optimization, loop analysis, and scheduling components. Flang is implementing this in MLIR via a special OpenACC MLIR dialect 5. It is our intention to use that as well, so NVIDIA is beginning to participate in the CIR/MLIR effort with a goal of accelerating the implementation and adoption of it, at least for the purposes of dialects. If this DOES NOT end up working by the time we’re ready for front-end code generation, we have identified and are prepared to implement a strategy where we can use LLVM-IR based metadata to enable the translation to the OpenACC MLIR dialect for the purposes of reusing those MLIR based passes.
Short term, we are going to start the Clang effort by implementing Parsing and Semantic Analysis of the directives, enabled by the -fopenacc flag, chosen for GCC compatibility. We will also implement a temporary flag to control the __OPENACC macro override (to be removed when we have a complete implementation), which will permit existing programs to be compiled with Clang to leverage our semantic analysis checking.
We believe this to be the best way to start for a few reasons. First, it permits us to make necessary progress while the Flang design and engineering of the shared components continues, so that we can help guide that effort, and start using the infrastructure and implementation when it is mature. We believe this will shorten the time required to develop OpenACC in Clang.
Second, it permits us to implement the OpenACC semantic analysis rules to the standard, such that Clang can be used to validate existing programs, thus becoming more immediately useful. This is possible because OpenACC directives are treated as advanced hints to the compiler, so ignoring them is a compliant implementation model, though we obviously intend to add the offload analysis as soon as it is available to do so.
We intend to leverage the existing tests from the NVHPC product, and development will follow the LLVM convention for lit tests, as well as use the lit tests written for CLACC. Additional testing/test suites are described below in the “A Test Suite” section.
While this is expected to be a multi-year project, we are excited to start implementing it.
Contribution Requirements: Clang - Get Involved
Evidence of a significant user community
The NVIDIA HPC compilers both have a sizable OpenACC community. Additionally, there is an annual OpenACC Computing Summit 6 that is well attended. CLACC has a number of users thanks to its support for Kokkos. While user numbers for GCC’s OpenACC implementation are unavailable, we believe that there is a significant user base, and that the presence of an upstreamed Clang implementation will only improve that situation.
Artificial Intelligence and other parallel computing tasks benefit from Offload; which OpenACC provides with a low barrier of entry, which we also anticipate will produce a growing user base.
Specific Need to reside within the Clang Tree
As OpenACC is a pragma based language that interacts closely with expressions and modifies code generation, it is necessary for it to be a part of Clang, and have its programming model be a part of LLVM. Additionally, we intend to use the OpenACC MLIR dialect5 (as currently being developed/used by the Flang community), which would require an LLVM based frontend to generate.
A Specification
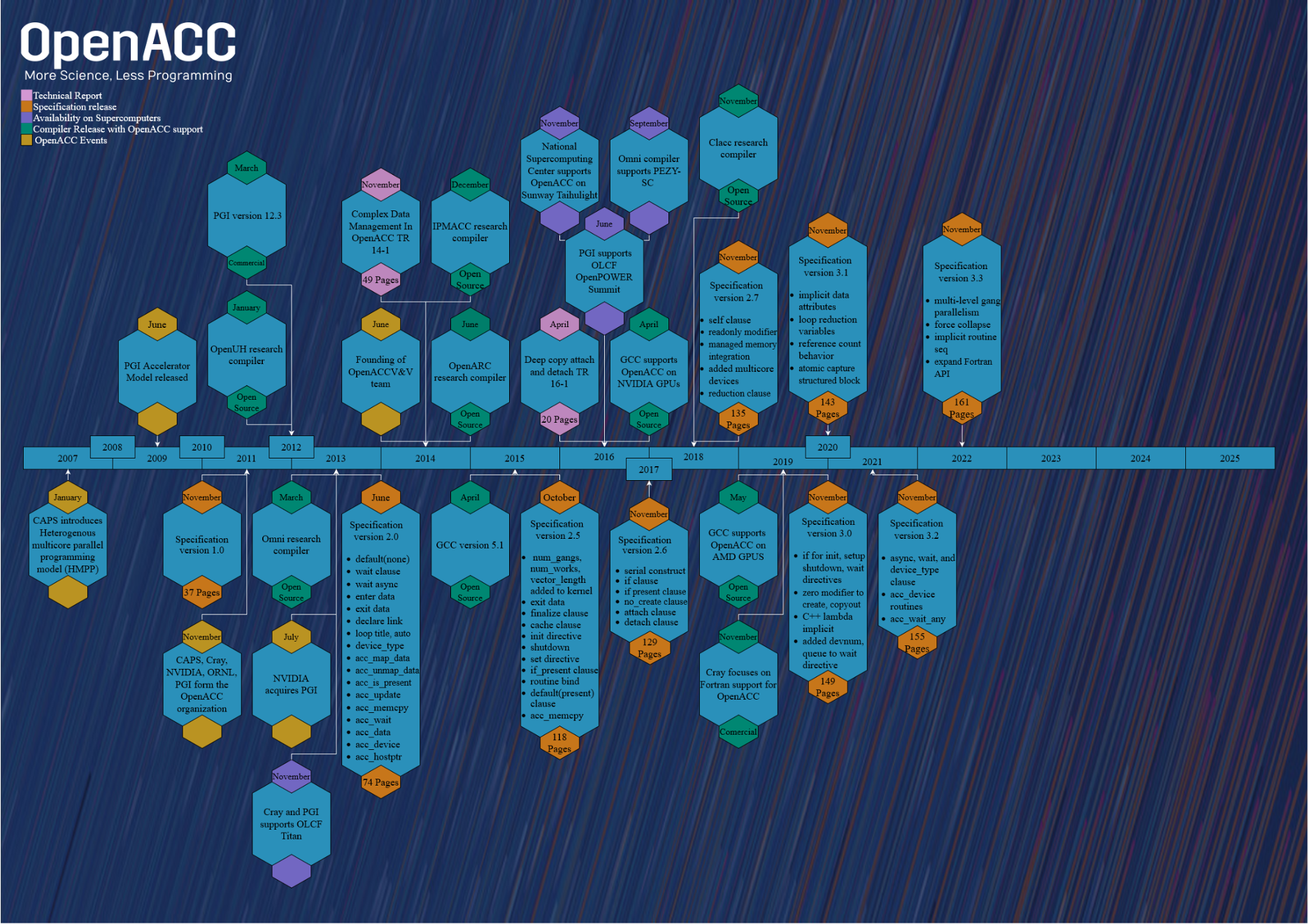
OpenACC has been an active standard since the release of the 1.0 specification in 2011 7. Since then, there have been 8 additional specifications released, with the current version being the OpenACC 3.3 specification 8, released roughly a year ago. The committee continues to meet frequently, and intends to continue releasing specifications.
{kind=link}
Representation within the appropriate Governing Organization
NVIDIA is active in the OpenACC Technical Committee, employing Jeff Larkin, the Technical Committee Chair, among other participants. Additionally, Duncan Poole and Jack Wells, also NVIDIA employees 9, are the chairman of the OpenACC board of directors and the president of OpenACC, respectively. NVIDIA has been active on the OpenACC Technical Committee since its inception, and intends to continue active participation for the foreseeable future.
Long Term Support Plan
NVIDIA as a company is dedicated to the success of OpenACC, as should be clear from our participation in the OpenACC standardization efforts and our commitment to implementing OpenACC in Flang, and is equally as committed to proliferating its use in multiple compilers. We intend to continue development and support of OpenACC in Flang and Clang in perpetuity via funding multiple compiler engineering developers. We are committed to this support.
High Quality Implementation
While we don’t yet have an implementation, we intend to do said implementation completely ‘upstream’ in Clang, where it is subject to extensive review and validation by the code owners and other contributors. Additionally, as the Attributes Code Owner (and primary reviewer as additional contributors start helping), I intend to ensure that every bit of code contributed meets or exceeds the LLVM and Clang coding standards and levels of quality.
A Test Suite
As we are developing in Clang directly, we intend to contribute extensive ‘lit’ tests. Additionally, the CLACC effort has resulted in a significant test suite that we intend to leverage along the way 5. For runtime-based testing, as the product matures, we also intend to develop and contribute runtime tests. There is also a current effort to add the UDel OpenACC V&V test suite 10 to the llvm test-suite 11. Finally, as OpenACC is an extensively used language, we will be leveraging existing open-source applications for runtime correctness and performance validation.
Patches
I’ve prepared 3 patches to start the implementation, however Github’s lack of a ‘patch stack’ has resulted in them all being in 1 pull request. At the conclusion of that pull-request, we’ll have -fopenacc, an _OPENACC macro defined to 1, plus a command line flag to override it for the purposes of validation, plus initial parsing support that diagnoses and recovers from all uses of #pragma acc. Please see the PR here: https://github.com/llvm/llvm-project/pull/70234.