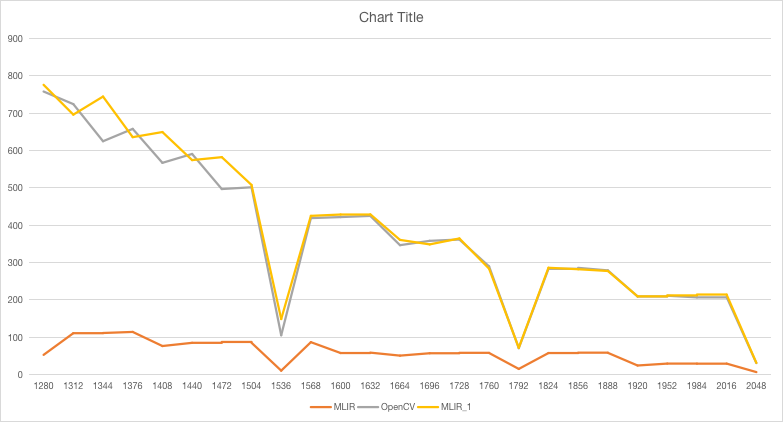
Hi everyone here:
Currently I’m trying to optimize Matmul, more clearly, I follow OpenCV fastGEMM implementation and write this:
#aptr_map_1 = affine_map<(d0)[s0] -> (d0 + 1, s0 - 1)>
#aptr_map_2 = affine_map<(d0)[s0] -> (d0 + 2, s0 - 1)>
#aptr_map_3 = affine_map<(d0)[s0] -> (d0 + 3, s0 - 1)>
#bptr_map = affine_map<(d0) -> (d0 + 16)>
#sub = affine_map<()[s0, s1] -> (s0 - s1 + 1)>
#map_broadcast = affine_map<(d0, d1) -> (0)>
module {
func.func @gemm(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>, %arg2: memref<?x?xf32>) {
%c0 = arith.constant 0 : index
%c32 = arith.constant 32 : index
%cst = arith.constant 0.000000e+00 : f32
%cf0 = arith.constant 0.000000e+00 : f32
%c1 = arith.constant 1 : index
%0 = memref.dim %arg0, %c0 : memref<?x?xf32> // i
%1 = memref.dim %arg0, %c1 : memref<?x?xf32> // k
%2 = memref.dim %arg1, %c1 : memref<?x?xf32> // j
affine.for %n = 0 to #sub()[%1, %c32] step 32 {
affine.for %m = 0 to %0 step 4 {
%aptr0 = memref.subview %arg0[%m, 0][1, %1][1, 1] : memref<?x?xf32> to memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>
%mark_1 = affine.min #aptr_map_1(%m)[%0]
%aptr1 = memref.subview %arg0[%mark_1, 0][1, %1][1, 1] : memref<?x?xf32> to memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>
%mark_2 = affine.min #aptr_map_2(%m)[%0]
%aptr2 = memref.subview %arg0[%mark_2, 0][1, %1][1, 1] : memref<?x?xf32> to memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>
%mark_3 = affine.min #aptr_map_3(%m)[%0]
%aptr3 = memref.subview %arg0[%mark_3, 0][1, %1][1, 1] : memref<?x?xf32> to memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>
%cptr0 = memref.subview %arg2[%m, 0][1, %1][1, 1] : memref<?x?xf32> to memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>
%cptr1 = memref.subview %arg2[%mark_1, 0][1, %1][1, 1] : memref<?x?xf32> to memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>
%cptr2 = memref.subview %arg2[%mark_2, 0][1, %1][1, 1] : memref<?x?xf32> to memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>
%cptr3 = memref.subview %arg2[%mark_3, 0][1, %1][1, 1] : memref<?x?xf32> to memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>
%md00 = memref.alloc() : memref<1xvector<16xf32>>
%_d00 = vector.transfer_read %cptr0[%c0, %n], %cst : memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>, vector<16xf32>
memref.store %_d00, %md00[%c0] : memref<1xvector<16xf32>>
%md01 = memref.alloc() : memref<1xvector<16xf32>>
%l_c_sub0 = affine.apply #bptr_map(%n)
%_d01 = vector.transfer_read %cptr0[%c0, %l_c_sub0], %cst : memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>, vector<16xf32>
memref.store %_d01, %md01[%c0] : memref<1xvector<16xf32>>
%md10 = memref.alloc() : memref<1xvector<16xf32>>
%_d10 = vector.transfer_read %cptr1[%c0, %n], %cst : memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>, vector<16xf32>
memref.store %_d10, %md10[%c0] : memref<1xvector<16xf32>>
%md11 = memref.alloc() : memref<1xvector<16xf32>>
%l_c_sub1 = affine.apply #bptr_map(%n)
%_d11 = vector.transfer_read %cptr0[%c0, %l_c_sub1], %cst : memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>, vector<16xf32>
memref.store %_d11, %md11[%c0] : memref<1xvector<16xf32>>
%md20 = memref.alloc() : memref<1xvector<16xf32>>
%_d20 = vector.transfer_read %cptr2[%c0, %n], %cst : memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>, vector<16xf32>
memref.store %_d20, %md20[%c0] : memref<1xvector<16xf32>>
%md21 = memref.alloc() : memref<1xvector<16xf32>>
%l_c_sub2 = affine.apply #bptr_map(%n)
%_d21 = vector.transfer_read %cptr2[%c0, %l_c_sub2], %cst : memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>, vector<16xf32>
memref.store %_d21, %md21[%c0] : memref<1xvector<16xf32>>
%md30 = memref.alloc() : memref<1xvector<16xf32>>
%_d30 = vector.transfer_read %cptr3[%c0, %n], %cst : memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>, vector<16xf32>
memref.store %_d30, %md30[%c0] : memref<1xvector<16xf32>>
%md31 = memref.alloc() : memref<1xvector<16xf32>>
%l_c_sub3 = affine.apply #bptr_map(%n)
%_d31 = vector.transfer_read %cptr3[%c0, %l_c_sub3], %cst : memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>, vector<16xf32>
memref.store %_d31, %md31[%c0] : memref<1xvector<16xf32>>
affine.for %k = 0 to %1 {
%a0 = vector.transfer_read %aptr0[%c0, %k], %cst {permutation_map = #map_broadcast} : memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>, vector<16xf32>
%a1 = vector.transfer_read %aptr1[%c0, %k], %cst {permutation_map = #map_broadcast} : memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>, vector<16xf32>
%a2 = vector.transfer_read %aptr2[%c0, %k], %cst {permutation_map = #map_broadcast} : memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>, vector<16xf32>
%a3 = vector.transfer_read %aptr3[%c0, %k], %cst {permutation_map = #map_broadcast} : memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>, vector<16xf32>
%b0 = vector.load %arg1[%k, %n] : memref<?x?xf32>, vector<16xf32>
%b_sub = affine.apply #bptr_map(%n)
%b1 = vector.load %arg1[%k, %b_sub] : memref<?x?xf32>, vector<16xf32>
%d00 = memref.load %md00[%c0] : memref<1xvector<16xf32>>
%d01 = memref.load %md01[%c0] : memref<1xvector<16xf32>>
%d10 = memref.load %md10[%c0] : memref<1xvector<16xf32>>
%d11 = memref.load %md11[%c0] : memref<1xvector<16xf32>>
%d20 = memref.load %md20[%c0] : memref<1xvector<16xf32>>
%d21 = memref.load %md21[%c0] : memref<1xvector<16xf32>>
%d30 = memref.load %md30[%c0] : memref<1xvector<16xf32>>
%d31 = memref.load %md31[%c0] : memref<1xvector<16xf32>>
%d00_ = vector.fma %a0, %b0, %d00 : vector<16xf32>
%d01_ = vector.fma %a0, %b1, %d01 : vector<16xf32>
%d10_ = vector.fma %a1, %b0, %d10 : vector<16xf32>
%d11_ = vector.fma %a1, %b1, %d11 : vector<16xf32>
%d20_ = vector.fma %a2, %b0, %d20 : vector<16xf32>
%d21_ = vector.fma %a2, %b1, %d21 : vector<16xf32>
%d30_ = vector.fma %a3, %b0, %d30 : vector<16xf32>
%d31_ = vector.fma %a3, %b1, %d31 : vector<16xf32>
memref.store %d00_, %md00[%c0] : memref<1xvector<16xf32>>
memref.store %d01_, %md01[%c0] : memref<1xvector<16xf32>>
memref.store %d10_, %md10[%c0] : memref<1xvector<16xf32>>
memref.store %d11_, %md11[%c0] : memref<1xvector<16xf32>>
memref.store %d20_, %md20[%c0] : memref<1xvector<16xf32>>
memref.store %d21_, %md21[%c0] : memref<1xvector<16xf32>>
memref.store %d30_, %md30[%c0] : memref<1xvector<16xf32>>
memref.store %d31_, %md31[%c0] : memref<1xvector<16xf32>>
}
%l_d00 = memref.load %md00[%c0] : memref<1xvector<16xf32>>
%l_d01 = memref.load %md01[%c0] : memref<1xvector<16xf32>>
%l_d10 = memref.load %md10[%c0] : memref<1xvector<16xf32>>
%l_d11 = memref.load %md11[%c0] : memref<1xvector<16xf32>>
%l_d20 = memref.load %md20[%c0] : memref<1xvector<16xf32>>
%l_d21 = memref.load %md21[%c0] : memref<1xvector<16xf32>>
%l_d30 = memref.load %md30[%c0] : memref<1xvector<16xf32>>
%l_d31 = memref.load %md31[%c0] : memref<1xvector<16xf32>>
vector.transfer_write %l_d00, %cptr0[%c0, %n] : vector<16xf32>, memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>
vector.transfer_write %l_d01, %cptr0[%c0, %l_c_sub0] : vector<16xf32>, memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>
vector.transfer_write %l_d10, %cptr1[%c0, %n] : vector<16xf32>, memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>
vector.transfer_write %l_d11, %cptr1[%c0, %l_c_sub1] : vector<16xf32>, memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>
vector.transfer_write %l_d20, %cptr2[%c0, %n] : vector<16xf32>, memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>
vector.transfer_write %l_d21, %cptr2[%c0, %l_c_sub2] : vector<16xf32>, memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>
vector.transfer_write %l_d30, %cptr3[%c0, %n] : vector<16xf32>, memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>
vector.transfer_write %l_d31, %cptr3[%c0, %l_c_sub3] : vector<16xf32>, memref<1x?xf32, affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>>
memref.dealloc %md00 : memref<1xvector<16xf32>>
memref.dealloc %md01 : memref<1xvector<16xf32>>
memref.dealloc %md10 : memref<1xvector<16xf32>>
memref.dealloc %md11 : memref<1xvector<16xf32>>
memref.dealloc %md20 : memref<1xvector<16xf32>>
memref.dealloc %md21 : memref<1xvector<16xf32>>
memref.dealloc %md30 : memref<1xvector<16xf32>>
memref.dealloc %md31 : memref<1xvector<16xf32>>
}
}
return
}
}
And test it by googlebenchmark, I find it’s performance is slow.

x axis is size, (e.g. 512x512x512)
Any suggestions here?
Thanks so much !