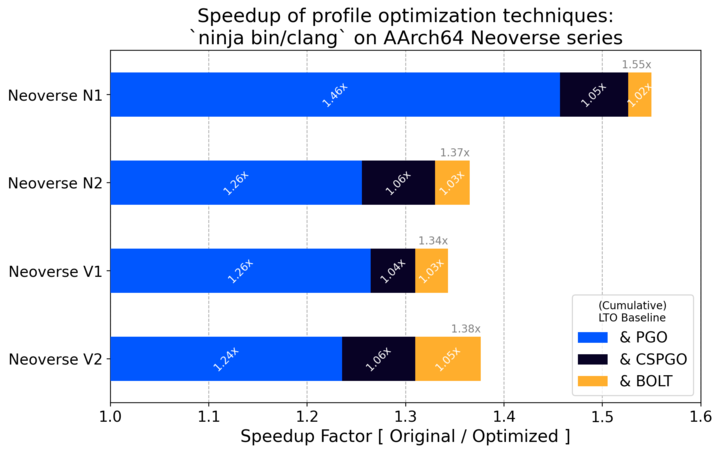
Hi! I’d like to share some performance results on AArch64 using PGO and BOLT. The attached graph illustrates the speedup, measured as seen with the elapsed time for a parallel build of bin/clang (version 19.1.6, built with clang-19.1.6). In each case, instrumented profiles were used with a build of libLLVMSupport used as training data.
It highlights the impact of various PGO techniques on AArch64. The Clang/BOLT version under test is main @ 2025-01-18, close to LLVM 20.
Note that clang will let you use cspgo without the intermediate steps, but in my experience this did not lead to the expected speedups unless it was combined with -fprofile-generate as described above.
Thanks a lot for all the details! Sorry for the delay
I thought you were using CSSPGO which is sample-based and rely on the LBR unit.
Have you tried CSSPGO on arm ? There are too few doc for CSSPGO.
Hi majiang, thanks for showing interest in pgo on arm. CSSPGO is not yet supported, we are working on enabling CSSPGO on AArch64 using BRBE (Branch Record Buffer extension)
I’m trying to replicate these sorts of results for a build of x86-64 clang, but seeing some surprising things. I’m doing a PGO+CSPGO+BOLT build as such:
-DLLVM_BUILD_INSTRUMENTED=IR to make pgo.profdata
-DLLVM_PROFDATA_FILE=pgo.profdata -DLLVM_BUILD_INSTRUMENTED=CSIR -DCMAKE_CXX_FLAGS='-mllvm -vp-counters-per-site=4' to make cspgo.profdata
Merge the two to make pgo_and_cspgo.profdata
-DLLVM_PROFDATA_FILE=pgo_and_cspgo.profdata to make the CSPGO-optimized build
BOLT optimization
However, I don’t see a huge speedup for CSPGO (versus same build without CSPGO), and the performance of this is worse than just doing frontend PGO instead of IR PGO+CSPGO. I’m using thin LTO for everything. So I’m curious, what sort of speedup do you see over frontend PGO here? And, are you able to share the exact commands you used to build it? @peterwaller-arm