Hi folks,
If anyone could answer the following questions or give any insight, that would be great. (As a newbie, not quite skilled in MLIR)
For my case, suppose that we have an Accel that can execute the tensor computation, let’s call it matrix multiplication unit (MMU), which differs from CPU in that the basic computation is the tile(vector/block) multiplication, not the elementwise multiplication.
So, I prefer to use MLIR to make the high-level expression, and then allow it to lower to the hardware code step by step. Here, there is a topic of how to express the data in tile or in vector in higher abstraction as the matrixes need to be sliced so that they can be fed to the mammal unit.
For example, assume that the MMU is [8,32]x[32,8], and when we have two matrixes as operands: A[48,128] and B[128,40], the first thing is to slice the two matrices into the several [32,8] and [8,64], individually, and then feed them to the MMU, which could be best illustrated in the following picture.
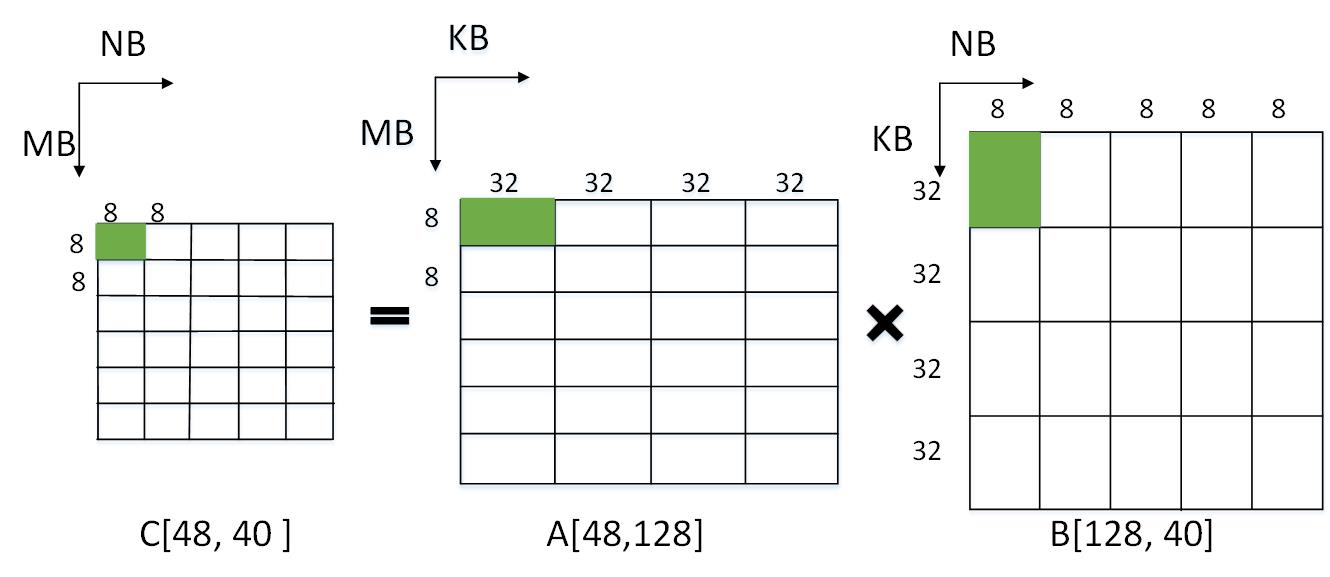
Have some investigations about expressing tile computation in MLIR done, they seem to be different from my situation. @bondhugula does a great job at the High-performance computation using MLIR and presents a wonderful example, but he targets the CPU and the generated code is mapped to elementwise multiplication. Also, vector dialect seems to be a potential choice, but not clear.
Overall, the questions are summarized as:
- Could the vector dialect abstract the tiling operation that slices a matrix into several sub-matrix?
ExtractSlicesOp can slice an N-D vector and return a tuple of slice vector, not clear about the next step involving iteration of the slice vectors as the tuple is not the supported type in MLIR. If going further, we should define the lowering pass, right? - Any better ideas for solving the above issue, like defining our own dialect?
Any advice is welcomed.
Thanks