Sharing a document I had written some time ago with an overview of dialects used in code generation and several observations for design evolution. Folks attending ODM have likely seen a previous version of the dialect diagram.
Author: @ftynse
Contributors: @nicolasvasilache @herhut @MaheshRavishankar @gcmn
Introduction
This document is a simplified overview of the code generation capabilities available in the MLIR infrastructure, in particular the parts available within the LLVM project codebase (“upstream” or “in-tree”). While it does occasionally mention users of MLIR outside of the LLVM project codebase, they are not analyzed in-depth and are only cited for illustrative purposes. The goal of this document is to serve as an entry point into the MLIR code generation infrastructure and to discuss how it can evolve in the future. It does not take into account the ongoing Splitting of the Standard Dialect
Current State
Classification
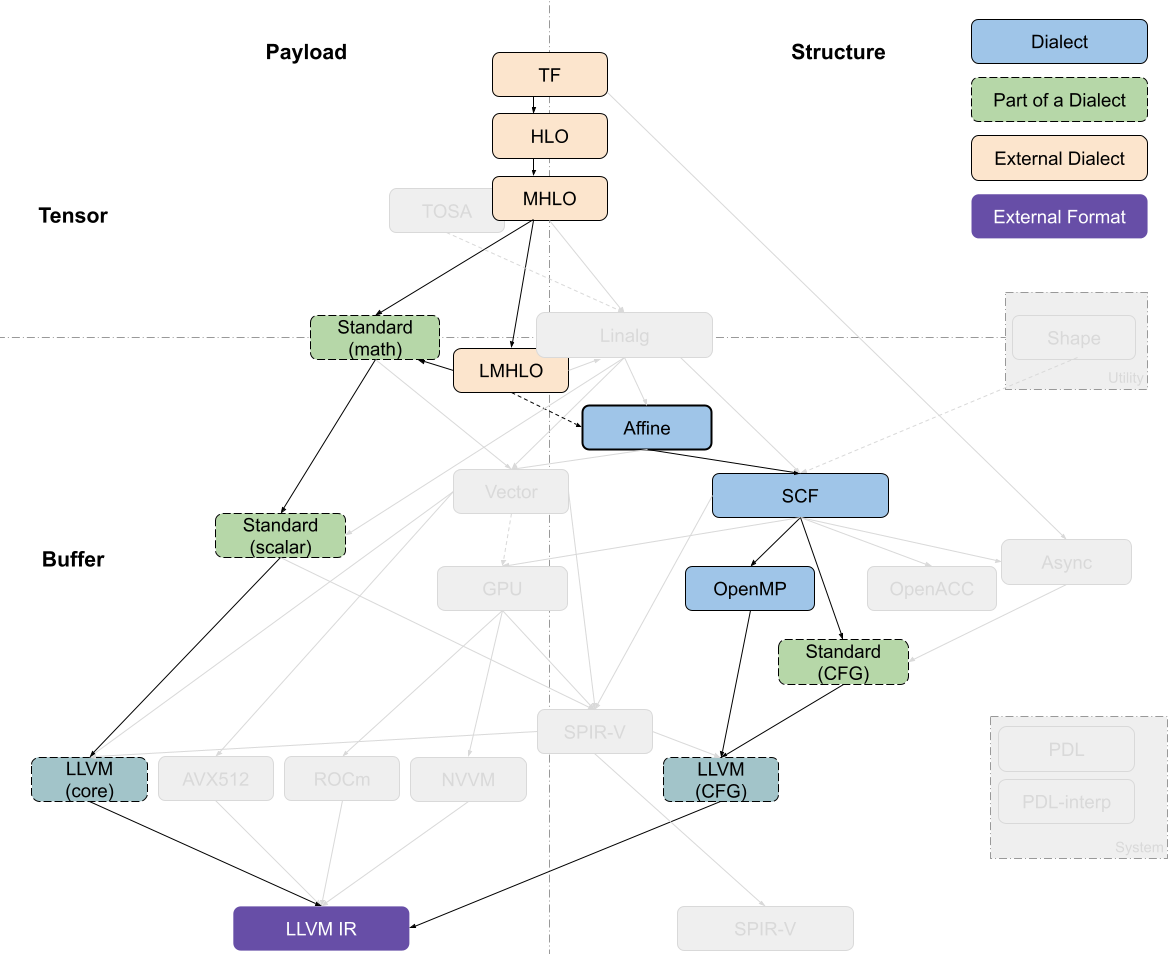
The multiple code generation-related dialects in MLIR can be roughly organized along two axes: tensor/buffer and payload/structure.
A dialect’s position on the tensor/buffer axis indicates whether its main data abstraction is a tensor as found in ML frameworks or a memory buffer as expected by conventional lower-level compilers. Tensors are treated as immutable values that are not necessarily associated with memory, that is, operations on tensors usually don’t have side effects. Data flow between such operations can be expressed using use-definition chains in traditional static single assignment (SSA) form. This is one of the aspects that makes MLIR a powerful transformation vehicle for ML programs, enabling simple rewriting of tensor operations. On the other hand, buffers are mutable and may be subject to aliasing, i.e. several objects may be pointing to the same underlying memory. Data flow can only be extracted through additional dependency and aliasing analyses. The transition between the tensor abstraction and buffer abstraction is performed by the bufferization procedure that progressively associates, and ultimately replaces, tensors with buffers. Several dialects, such as Linalg and Standard, contain operations on both tensors and buffers. Some Linalg operations can even operate on both at the same time.
A dialect’s position on the payload/structure axis indicates whether it describes what computation should be performed (payload) or how it should be performed (structure). For example, most mathematical operations in the Standard dialect specify the computation to be performed, e.g., the arctangent, without further detail. On the other hand, the SCF dialect defines how the contained computation is performed, e.g., repeated until some runtime condition is met, without restricting what the condition is and what computations are performed. Similarly, the Async dialect denotes the general execution model applicable at various levels of payload granularity.
This position on this axis is non-binary, especially at higher level of abstraction. Many operations at least partially specify the structure. For example, vector dialect operations imply SIMD execution model. During the compilation process, the instructions of “how” tend to become more detailed and low-level. Simultaneously, lower levels of the abstraction stack tend to separate the structure operations from the payload operations for the sake of transforming only the former while keeping only an abstract understanding of the payload, e.g., the accessed data or the estimated cost.

Dialects of Interest
An MLIR code generation pipeline goes through a sequence of intermediate steps, which are characterized by the most recently introduced dialect. Dialects can be roughly organized into a stack based on the level of abstraction they feature. Converting the representation from a higher-level abstraction to a lower-level abstraction, i.e. lowering, is usually straightforward whereas the inverse process may not be.

Most pipelines enter the in-tree dialect infrastructure through the Linalg dialect, which features a versatile representation of structured computation on structured data. The dialect is specifically designed to support various transformations with minimal analysis. Operations in this dialect support both tensor and buffer operands and the bufferization process can happen without changing the operations themselves. Furthermore, Linalg provides “named” operations with specific payload, such as matrix multiplication and convolution, and “generic” operations that only define the structure. Conversions are available between the two forms. The inherent iterative structure of Linalg dialect operations allows them to be converted into vector operations as well as (affine) loops around vector or scalar operations.
The Async dialect captures a general asynchronous programming model and may appear at different levels: at a higher level where it is used to[organize large chunks of computation across and within devices, and at a lower level where it can wrap sequences of primitive instructions.
The Vector dialect (Note that the vector type belongs to the built-in dialect and can be used outside of the Vector dialect.) is a mid-level abstraction for SIMD and, potentially, SIMT execution models. It leverages MLIR’s multidimensional vector type to target different platforms through dedicated lower-level dialects. An ongoing work investigates the use of vector abstraction to target GPU devices (SIMT) through explicit representation of threads.
The Affine dialect is MLIR’s take on polyhedral compilation. It encapsulates the restrictions of the related programming model and defines the corresponding operations, namely control flow structures such as affine loops and conditionals and affine counterparts of memory operations. Its primary goal is to enable polyhedral transformations, such as auto-parallelization, loop fusion and tiling for locality improvement, and loop vectorization in MLIR.
The SCF (Structured Control Flow) dialect contains the common control flow concepts expressed at a higher level than branches in a control flow graph (CFG), e.g., (parallel) “for” and “while” loops as well as conditionals. This dialect is used to represent, and sometimes transform, the structure of the computation without affecting the payload. It is a common lowering target from Affine and Linalg, which may also be used as an entry point to the MLIR code generation infrastructure from lower-level representations such as C.
Various programming models, namely GPU/SIMT, Async, OpenMP and OpenACC can be obtained from the SCF dialect. Each of these models is represented by a corresponding dialect, the operations in which are rarely subject to further optimizing transformations. However, these representations are an opportunity to implement transformations specific to the programming model, e.g., ones currently explored for the Async dialect.
SCF can also be converted to the “standard” CFG representation by replacing structured control flow with branches between blocks. The branch operations are currently contained in the Standard dialect, together with numerous other operations at various abstraction levels. For example, the Standard dialect also contains pointwise operations on tensors and vectors, conversions between buffers and tensors, trigonometric operations on scalars, etc. Therefore, the Standard dialect is in the process of being split into multiple well-defined dialects.
Ultimately, parts of the Standard dialect (operations on scalars and vectors, and branches) are converted into target-specific dialects that mostly serve as exit points from the MLIR code generation infrastructure. These include the LLVM, NVVM, ROCDL, AVX, Neon, SVE and SPIR-V dialects, all of which correspond to an external format, IR or instruction set. These dialects are not subject to transformation except for canonicalization.
Finally, the Shape dialect is used to describe shapes of data independently of the payload or (mostly) structure. It appears at the entry level of the code generation pipeline and is typically lowered into address arithmetic or canonicalized away.
PDL (Pattern Description Language) and PDLInterp dialects are used by the next-generation pattern-rewriting infrastructure for MLIR to specify transformations. As such, they never appear in the code generation pipeline, but may be necessary to describe its operation.
Some Existing Pipelines
TensorFlow Kernel Generator

The Tensorflow Kernel Generator project, starting at the TensorFlow (TF) dialect, has recently switched to targeting Linalg-on-tensors from MHLO (Meta HLO, more suitable for compilation thanks to, e.g., removal of implicit broadcasting, and with support for dynamic shapes; where HLO is High-Level Optimizer representation, derived from XLA) instead of LMHLO (Late MHLO, same as MHLO but on buffers rather than tensors) and performs fusion at that level before calling bufferization on Linalg. Further loop transformations such as tiling happen at the SCF level, which is then converted into target-specific GPU dialect while the payload operations are converted to the LLVM dialect with Standard as intermediary. Now-retired prototypes have experimented with using LMHLO dialect targeting Linalg-on-Buffers and performing all transformations on SCF, where it may be more complex than on tensor abstraction.
When producing several kernels, TensorFlow-related flows are expected to use the Async dialect to orchestrate computation.
IREE Compiler (LLVM Target)

IREE(Intermediate Representation Execution Environment) has its own high-level representation with a set of dialects which, for code generation purposes, are currently evolving to target Linalg-on-tensors. IREE-specific dialects are mostly dedicated to organizing the computation payload, which can be expressed (currently) as MHLO, TOSA, Linalg-on-tensors, etc. The majority of transformations happen within Linalg, at either tensor or buffer level, along with bufferization. The preferred path to the executable goes through the Vector dialect, where additional transformations can take place. SCF can be used for control flow around vector operations when lowering from Linalg, but no transformations are performed on these operations. Targeting SCF essentially means no further structure optimization will be performed. The Vector dialect can be progressively lowered into less complex abstractions it includes until ultimately targeting the LLVM dialect.
IREE Compiler (SPIR-V Target)

SPIR-V (Standard Portable Intermediate Representation, Khronos group standard.) is a major target for the IREE compiler. The top-level flow is similar to the one targeting LLVM IR, with the majority of transformations happening at the Linalg on tensors and Vector levels. From there, the lowering conversions tend to go directly to the SPIR-V that has a rich set of operations spanning multiple levels of abstractions: high-level operations, structured control flow and instruction-like primitives. This flow goes through the GPU dialect for device-only operations such as workitem identifier fetchers and relies on IREE’s runtime for managing GPU kernels.
Recent work allows IREE to target the GPU dialect from the Vector dialect, exposing GPU threads as vector lanes (at either warp or block level). Similarly, some conversions are available from Linalg and Vector to SPIR-V directly, bypassing the intermediate stages, but will likely be replaced with a more gradual lowering approach.
Polyhedral Compiler
A hypothetical polyhedral compilation flow starting at HLO and bypassing Linalg can proceed by targeting the Affine dialect from the LMHLO or any other bufferized form of the operations. In this case, the majority of transformations happen on the Affine dialect, which is the main abstraction currently supported by polyhedral transformations. The code is then lowered to SCF control flow and Standard memory operations, before being further converted to platform-specific abstractions such as OpenMP or GPU.
The polyhedral model also supports early vectorization, going from Affine control flow constructs to the Vector dialect as opposed to discovering loop vectorization opportunities later.
It has been historically important for a polyhedral compiler to be able to accept code expressed in lower-level abstractions such as the C programming language. It can be currently achieved through progressive raising [1, 2].
Analysis
Crossing Dialects
In hindsight, it appears that the dialects that cross axis boundaries in this classification (GPU, Linalg and Vector) have required the most discussion and iteration before being accepted as part of the core ecosystem. Even now, users of MLIR infrastructure reported that it was challenging to understand the positioning of some dialects. For example, IREE uses parts of the GPU dialect related to on-device execution, but not the parts related to managing data and kernels from the host, which are closer related to the structure than to the payload. Similarly, the discussion on bridging the tensor and memref abstraction with corresponding operations required significant effort to converge.
This suggests that new dialects, or smaller IR concepts, can be easier to discuss and reach consensus if they are clearly positioned with respect to other dialects and the design space. When it is necessary to cross the gap between abstractions, it may be preferable to discuss it separately and aim for generalization between dialects (e.g., bufferization process).
Linalg at the Center
The Linalg dialect is one of the main entry points to the MLIR code generation pipelines. Its most recent evolution makes it operate on both tensors and buffers, making bufferization an intra-dialect transformation. It has sufficiently high-level information about the operations to perform transformations without expensive analyses, especially when operating on tensors as values. Some transformations like fusion of element-wise operations and tiling, and combination thereof to generate imperfectly nested computations capture a sufficient amount of transformations needed to target a broad range of architectures. Furthermore, the concept of named operations enables payload-carrying operations that build on the computational patterns of Linalg.
Being exercised in virtually all compilation pipelines adds maintenance pressure and stability requirements on Linalg as production users start to rely on it. The fact that it works across buffers and tensors, and may capture both the payload and the structure of the computation makes understanding Linalg to some extent a requirement for understanding any MLIR code generation pipeline. While there are benefits in having one well-defined and maintained entry point, extra care must be taken to ensure that Linalg remains composable with other dialects and that transformation algorithms are not over-designed for it.
Pipeline Differences to Complementary Transformations
Several parallel compilation pipelines appear to emerge in the ecosystem. The case of targeting GPUs is particularly illustrative: optimizing transformations, parallelism detection and device mapping decisions can happen in various dialects (Linalg, Affine, SCF), which may end up partially reimplementing each other’s functionality; device mapping can derive SIMT threads from explicit loops or from vectors, using the SCF or the Vector dialect. Finally, GPU libraries have support for higher-level operations such as contractions and convolutions, that could be directly targeted from the entry point of the code generation pipeline.
It is more important than ever to make sure representations and transformations compose and complement each other to deliver on MLIR’s promise to unify the compilation infrastructure, as opposed to building independent parallel flows. It does not necessarily mean immediately reusing all components, but avoid poorly composable patterns as much as possible. The utility of domain- and target-specific compilers is undeniable, but the project may need to invest into cross-cutting representations, using the generic mechanisms of attributes and interfaces. Circling back to targeting GPUs as an example, a device mapping strategy expressed as attributes that can be attached to different operations (e.g., Linalg generics or parallel SCF loops) that can be transformed through interfaces without needing to know the details of a specific operation.
Build Small Reusable Abstractions
One can observe an unsurprising tendency of performing most transformations in the higher levels of the code generation pipeline: the necessary validity information is readily available or easily extractable at these levels without the need for complex analyses. Yet, higher levels of abstraction often have more stringent restrictions of what is representable. When pursuing benefits of such abstractions, it is important to keep in mind the expressivity and the ability to perform at least some transformations at lower levels as means to quickly increase expressivity without reimplementing the top-level abstraction (dynamic shapes in HLO are a good example).
Need for More Structure
Another emerging tendency is larger dialects and progressive lowering performed without leaving the dialect boundaries. Some examples include Linalg operations on tensors that get transformed into using buffers, GPU dialect block reductions that get decomposed into shuffles, and math operations in Standard that can be expanded into smaller operations or approximated using other Standard operations. We are reaching a point where a dialect contains several loosely connected subsets of operations. This has led to the proposal of splitting the Standard dialect into multiple components. However, the splitting may not always be desirable or even feasible: the same Linalg operations accept tensors and buffers so it is challenging to have separate TLinalg and BLinalg without lots of duplication. This calls for additional ways of structuring the operations within a dialect in a way that is understandable programmatically.
Host/Device Or Program/Kernel As Additional Axis
Finally, uses of MLIR in the scope of larger, mostly ML-related, flows prompt for cleaner separation between the aspects that pertain to the overall organization of computations (e.g., operations that reflect the mapping of a model on a distributed system and interaction with the framework that embeds MLIR, typically on a “host”) and organization of individual computations (e.g., operations that correspond to internals of a “kernel” or another large unit of computation, potentially offloaded to a “device”). For “host” parts, code generation may also be necessary and often requires different transformations than for “kernel” parts.
Specific examples of this separation include the GPU dialect that contains operations for both controlling the execution from host and operations executed on the GPU proper, which may benefit from separation into independent dialects, and the Async dialect that is being used on two levels: organizing the execution of independent “kernels” and parallelizing execution within a “kernel” by targeting LLVM coroutines.