Hi,
This is a proposal about implementing strided memory access vectorization.
Currently LLVM does not support strided access vectorization completely, some support is available via Interleave vectorization.
There are two main overheads with strided vectorizations:
- An overhead of consolidating data into an operable vector.
- An overhead of distributing the data elements after the operations.
Because of these overheads LLVM finds strided memory vectorization is not profitable and generating serial code sequence over vectorized code.
GATHER & SCATTER instruction support is available on few(not all) targets for consolidation & distribution operations.
In this approach we are trying to handle cases like this:
for (int i = 0; i < len; i++)
a[i*3] = b[i*2] + c[i*3];
We model strided memory load & store using shuffle & load/mask-store operations.
- Load is modeled as loads followed by shuffle.
- Store is modeled as shuffle followed by mask store.
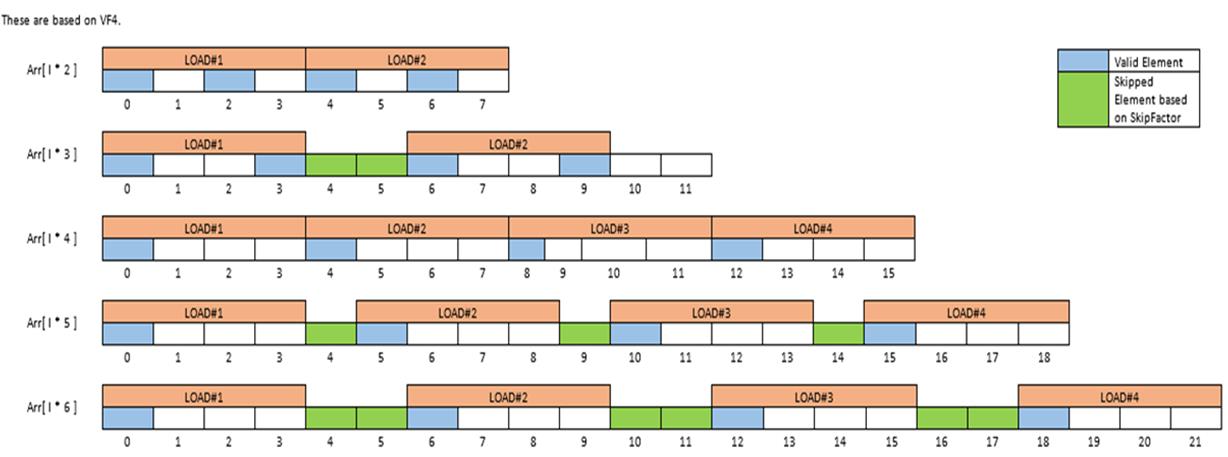
- To minimize load and store operation introduced ‘SkipFactor’.
‘SkipFactor’:
- Multiple load operation required for consolidating data into an operable vector.
- Between various loads we skip by few offsets to effective consolidate.
- SkipFactor is the number of additional offsets required to move from the previous vector load memory-end address for the next vector load.
- SkipFactor allows all memory loads to be considered as identical (From valid element perspective).
- SkipFactor = (Stride - (VF % Stride)) % Stride)
For example:
How LOAD is modeled:
Load stride 3 (i.e. load for b [ 3 * i ])
%5 = getelementptr inbounds i32, i32* %b, i64 %.lhs
%6 = bitcast i32* %5 to <4 x i32>*
%stride.load27 = load <4 x i32>, <4 x i32>* %6, align 1, !tbaa !1
%7 = getelementptr i32, i32* %5, i64 6
%8 = bitcast i32* %7 to <4 x i32>*
%stride.load28 = load <4 x i32>, <4 x i32>* %8, align 1, !tbaa !1
%strided.vec29 = shufflevector <4 x i32> %stride.load27, <4 x i32> %stride.load28, <4 x i32> <i32 0, i32 3, i32 4, i32 7>
How STORE is modeled:
Store with stride 3 (i.e. store to c [ 3 * i ])
%10 = getelementptr inbounds i32, i32* %c, i64 %.lhs
%11 = bitcast i32* %10 to <4 x i32>*
%interleaved.vec = shufflevector <4 x i32> %StoreResult, <4 x i32> undef, <4 x i32> <i32 0, i32 undef, i32 undef, i32 1>
call void @llvm.masked.store.v4i32(<4 x i32> %interleaved.vec, <4 x i32>* %11, i32 4, <4 x i1> <i1 true, i1 false, i1 false, i1 true>)
%12 = getelementptr i32, i32* %10, i64 6
%13 = bitcast i32* %12 to <4 x i32>*
%interleaved.vec30 = shufflevector <4 x i32> %StoreResult, <4 x i32> undef, <4 x i32> <i32 2, i32 undef, i32 undef, i32 3>
call void @llvm.masked.store.v4i32(<4 x i32> %interleaved.vec30, <4 x i32>* %13, i32 4, <4 x i1> <i1 true, i1 false, i1 false, i1 true>)
NOTE: For Stride 3 SkipFactor is 2, that’s why the second GEP offset by 6(4+2).
To enable this feature below LLVM changes required.
- Identify strided memory access (Its already there i.e. interleave vectorizer does this)
- Costing changes:
- Identify number of Load[s]/Store[s] & Shuffle[s] required to model Load/Store operation by considering SkipFactor.
- Return total cost by adding Load[s]/Store[s] and shuffle[s] costs.
- Transform:
- Generate Shuffle[s] followed by Mask-Store[s] instructions to model a Store operation.
- Generate Load[s] followed by Shuffle[s] instructions to model a Load operation.
Implemented a working prototype to demonstrate this feature, its available at below review-thread.
http://reviews.llvm.org/D21363
Use below option to enable this feature:
“-mllvm -enable-interleaved-mem-accesses -mllvm -enable-strided-vectorization”
Gains observed with prototype**:**
TSVC kernel S111 1.15x
TSVC kernel S1111 1.42x
If community is interested in the above work, I have below plan:
I’m not sure keeping this feature separate or the part of current interleave vectorizer ?
- Will enable interleave vectorizer on X86 (If this feature is going as an enhancement on interleave vectorizer)
- If it’s going with interleave vectorizer, will modify its infra to support this.
- Will enable strided vectorization by submitting changes on costing & transform.
Please share your valuable thoughts.
Thanks,
Ashutosh